The Waiting Paradox: An Intro to Probability Distributions
How much longer do I have to wait for my bus?


Who doesn’t know the feeling: You walk to a bus stop, wait for the bus and… you wait. And then you wait a little bit more. And a little bit more. Somebody told you that the buses, on average, arrive every 10 minutes. And now you’ve already been waiting for 10 minutes. Shouldn’t the bus have arrived by now? And the more urgent question: How much longer are you going to wait for?
The answer is: It’s for 10 minutes. It’s for 10 minutes if you assume the time between the arrival of any two buses to be exponentially distributed.
It’s paradox and surprising, but it’s true. And it’s called the Waiting Paradox. It is one of my favorite paradoxes in Math. I love it so much that I sometimes randomly start telling it to random strangers while we’re waiting for a bus at the bus stop.
They usually think I’m crazy.
That’s okay.
To understand the Waiting Paradox, we first need to understand probability distributions. What are probability distributions?
(Continuous) Probability Distributions
A random variable is a variable, where the values are not deterministic, but depend on randomness. A probability distribution is a function that describes all the possible values of such a random variable X and the probabilities of these values the variable may take.
We can generally divide probability distributions into two categories:
- Discrete and
- Continuous.
Discrete means that our random variable can only take finitely many or at least countable infinitely many values. In the continuous case, the random variable can take an uncountably infinite amount of values. In most cases, it basically means that discrete random variables take numbers such as 1, 2, 3… and continuous random variables can be any real number.
Great examples of discrete random variables are coin or die tosses, population sizes, etc.
Great examples of continuous random variables are distances covered, body height, body weight and so on — basically, everything that may be any real-valued number or some subset of the real numbers.
In this story, we will only talk about continuous probability distributions.
(Continuous) probability distributions can be described using the cumulative probability distribution function, usually denoted by F(x). If F(x) is differentiable, i.e. the derivative of this function F(x) exists, the derivative is called a probability density function and is denoted by f(x).
Side note: In fact, F(x) only needs to be differentiable almost everywhere, but for the examples we’ll use, we can just say that F(x) needs to be differentiable and f(x) is the derivative of F(x).
The Cumulative Distribution Function (cdf F(x))
The cumulative probability distribution function F(x) = P(X ≤ x) of a random variable X, also called the cdf, has mainly two properties:
- it is monotonously increasing
- it takes values between 0 and 1.

The Probability Density Function (pdf f(x))
The probability density function f(x), also called the pdf, has mainly two properties:
- it only takes positive values
- the area between f(x) and the x-axis is 1.
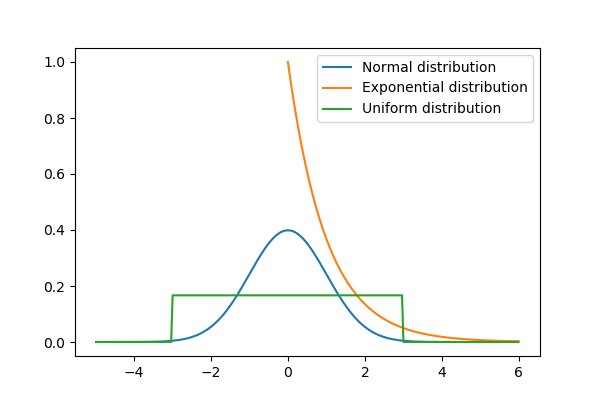
The pdf of a probability distribution does not necessarily exist whereas the cdf always exists, even though we may not always be able to write it down using the standard functions we know. A wonderful example of this is the normal distribution, where people usually know the famous bell curve which is its pdf, but for the cdf, we usually just write the integral of the pdf instead of writing it explicitly.
If the pdf exists, we can use it to calculate the expected value of a random variable X.
The Expected Value E(X)
The expected value E(X) of the continuous random variable X is then given by
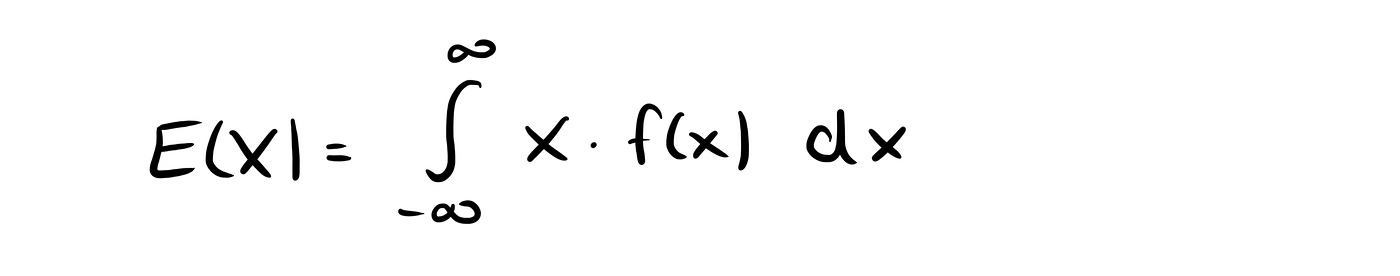
What’s the interpretation of the expected value?
Well, the name is a little bit misleading, because it’s not the value you would expect, but instead, it is the average value that a random variable will take if we only repeat our experiment often enough! In fact, we may never observe the expected value.
Let me give you an example to understand this. Let’s say we run a (discrete) experiment with an expected value of 0.5 a number of 1000 times. If we sum up all of the observations and divide them by 1000, it will be quite close to our expected value of 0.5. This is due to a Theorem called the Law of Large Numbers.
For example, just imagine you throw a coin 1000 times. If you get heads, you earn 1 point. If you get tails, you earn 0 points. The random variable X describes the number of points you score when throwing the coin once.
If it’s a fair coin, it’s expected value is
E(X) = 0.5 * 1 + 0.5 * 0 = 0.5,
which is calculated using the true definition of the expected value.
Also, after throwing the coin 1000 times, you should have earned around 500 points after 1000 throws and thus the expected value would be 500/1000=0.5 — but that’s a value we’ll never reach when throwing the coin!
The Exponential Distribution
Let’s get to the exponential distribution. It’s my favorite probability distribution. Why? Because it’s simple, beautiful and full of surprises.
The cdf of the exponential distribution for a parameter λ >0 is given by
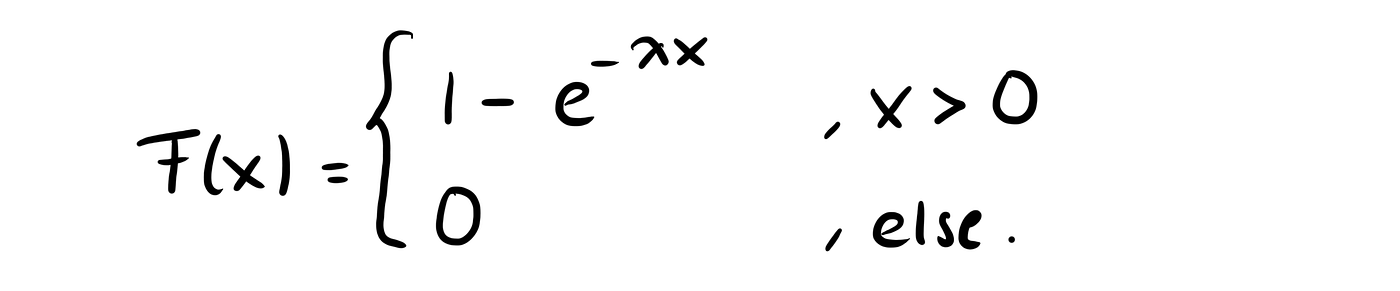
And the pdf is given by
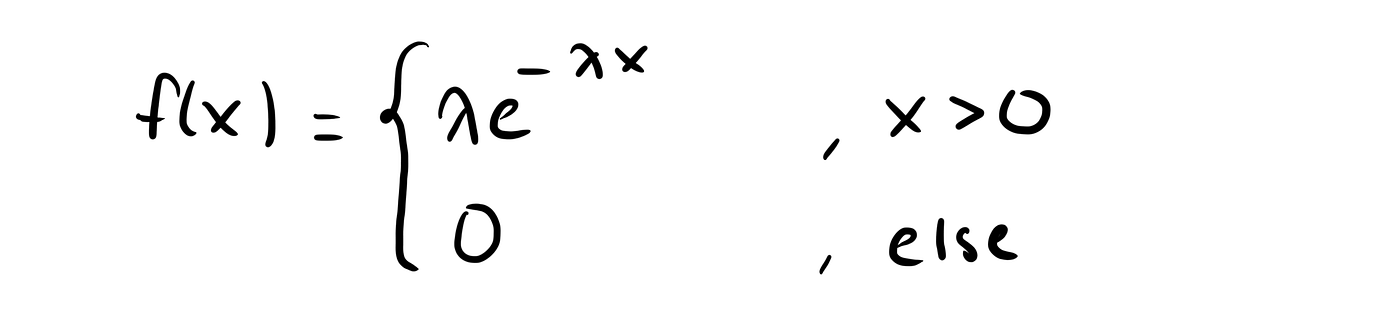
We can then calculate the expected value by
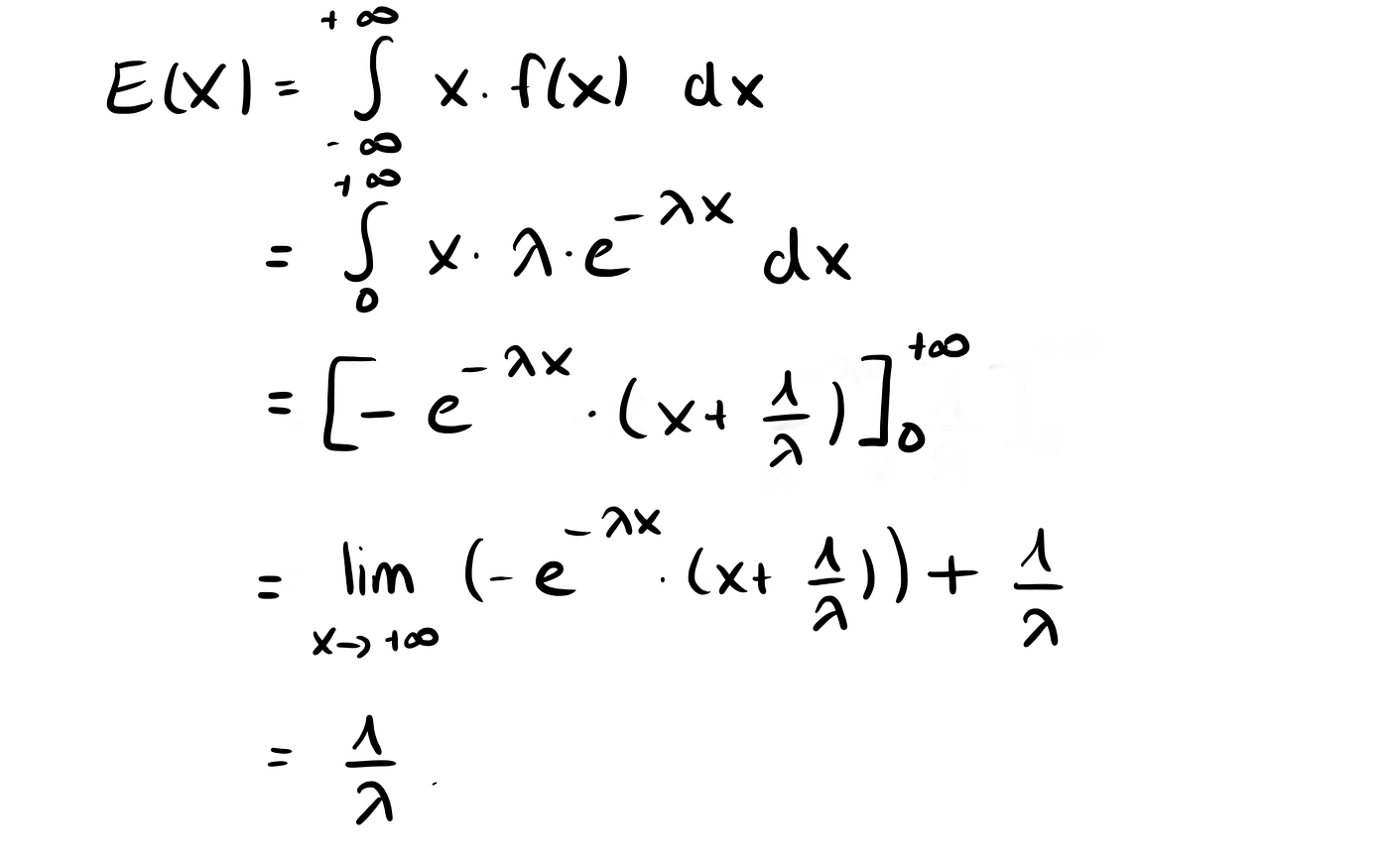
We can also draw the pdf for a few different parameters λ, for example for λ=0.3, λ=1 and λ=3 to see how it behaves.

The Waiting Paradox
Let’s get back to the Waiting Paradox now. We assume that the times between any two arrivals are independent and exponentially distributed with λ = 0.1 minutes. This means, that the expected time between two arrivals is
E(X) = 1/ λ = 1/0.1= 10
minutes or that on average, buses arrive every 10 minutes.
Let X be the random variable that describes the time between two arrivals.
Let’s now say that there have already passed s minutes since the last bus arrived. What is the probability that we have to wait another t minutes, i.e. the probability that the time between the two arrivals is s+t or in mathematical terms, what is
P(X > s+t | X >s)?
Well, we can calculate this. And the answer is, it’s the same as if we had never waited at all and we have to wait t minutes, it’s P(X >t).
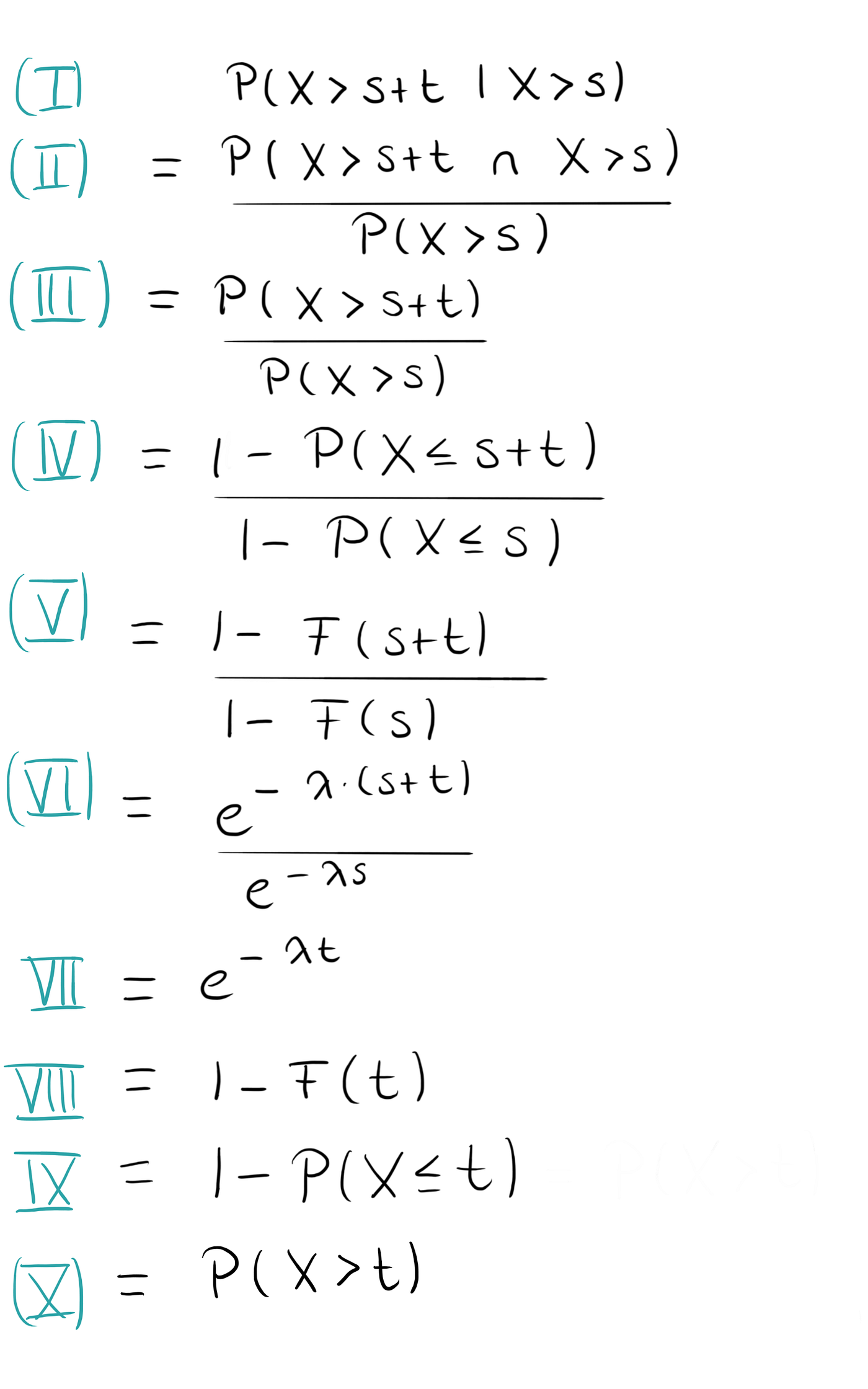
This is quite paradoxical and surprising at first!
This property is also the reason why, no matter what time we get to the bus station, if the buses arrive on average every 10 minutes, we will still have to wait for another ten minutes (at least on average). To make this a little bit more obvious, we could also calculate the conditional expected value of X given that X is greater than s, i.e. we calculate the expected total waiting time given that we have already waited s minutes.
Then holds
E(X | X > s) = E(X) + s.
Again, the interpretation is the same, no matter how much time s we have already waited, we are still expected to wait for 1/λ minutes more.
The calculation for this is a bit trickier, so feel free to skip this part (or indulge, if you are interested).
We want to calculate
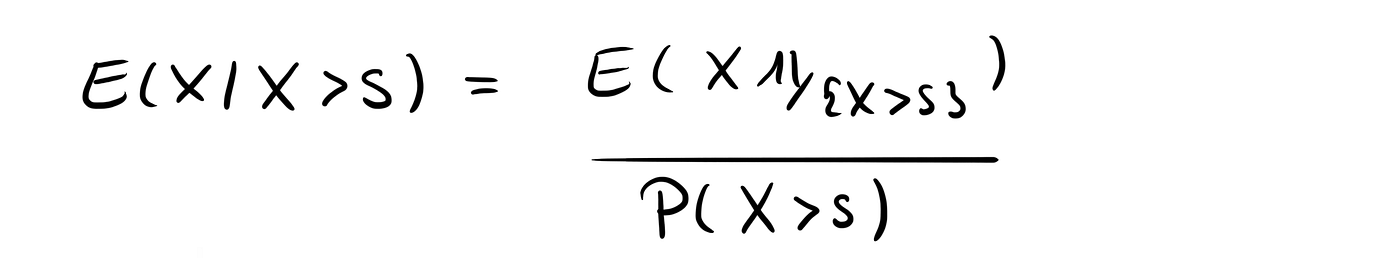
where the 1 with the double-line is the so-called indicator function. To do this, we first calculate the nominator.
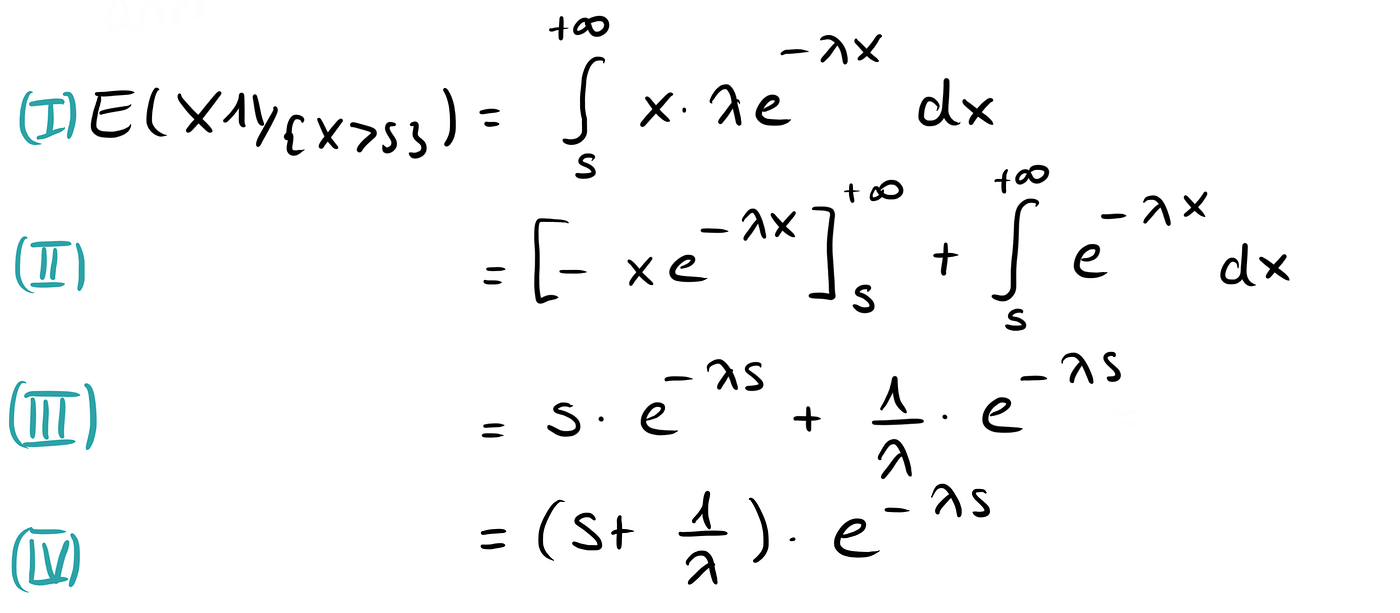
We then get the desired result

That’s it.
Why does the Waiting-Paradox only work with Exponential Distributions?
The Waiting Paradox works because of the exponential distribution. In fact, the exponential distribution is the only continuous distribution for which it holds true.
For all of the other distributions, it won’t work. There is an intuitive explanation for this. With the exponential distribution, the times between any two arrivals are not evenly distributed, but exponentially. This means, that sometimes the times between two arrivals may be very large, but often it will be very small.
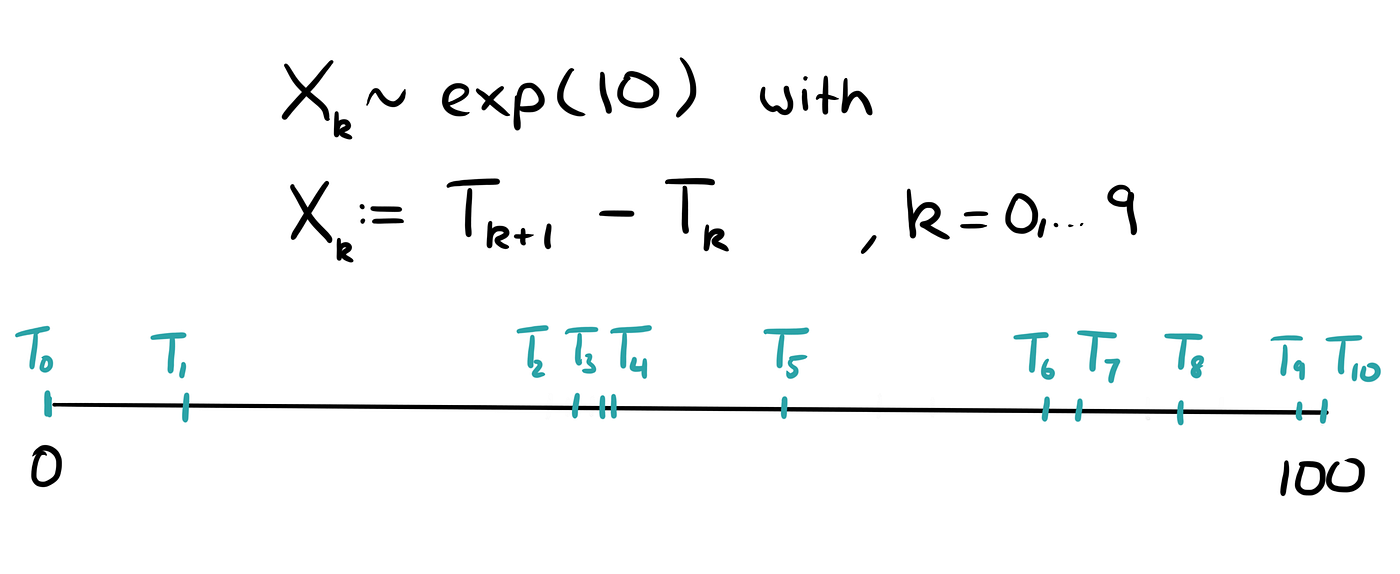
Thus, it is more likely that we are caught in a long waiting period instead of a short one.
If we, for example, lived in a perfect world where the buses arrive every 10 minutes (i.e. there is no more randomness) and we arrived at a random time, i.e. uniformly distributed between 0 and 10 minutes after the last bus had arrived, we would wait, on average, for 5 minutes.
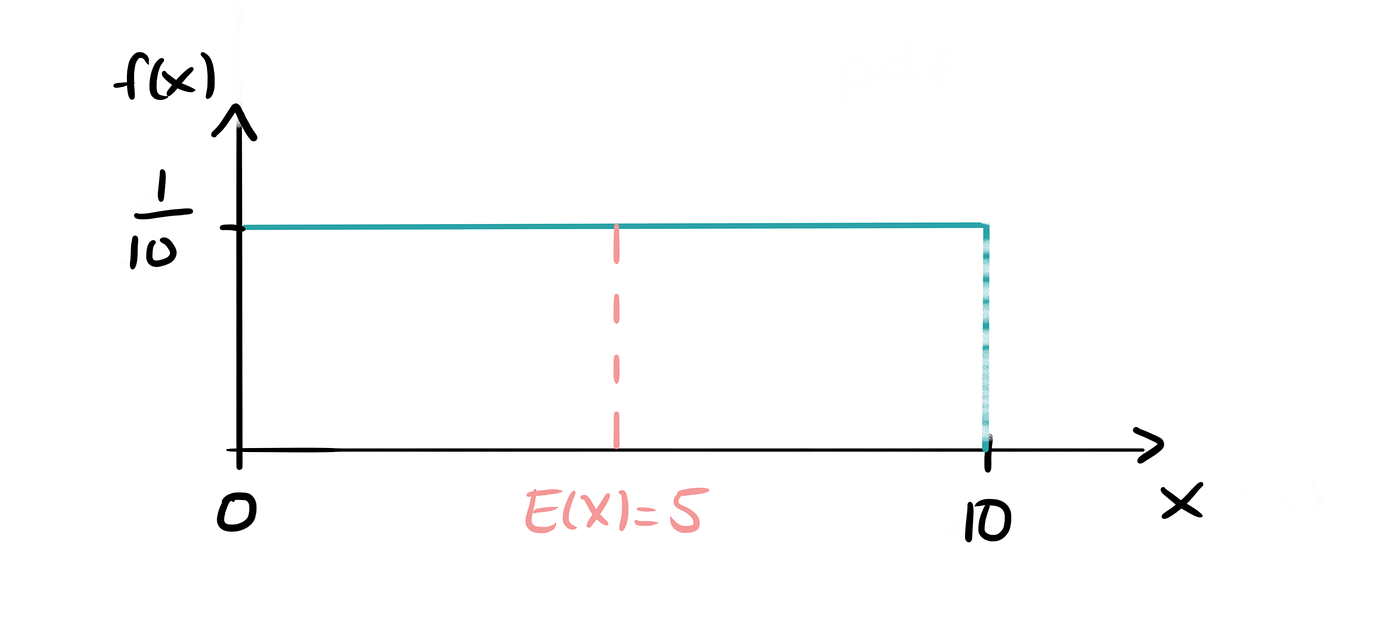
This is because of the even spacing between any two arrivals. If we get to the bus stop at a random time, the chances of catching a very large waiting gap will be relatively small. Also, the chances of two buses arriving immediately after one another are a lot smaller compared to the exponential distribution.
But wait,… How about Real Life?
This is mathematics, who cares about what really happens in real life? Well, I’m just kidding. When buses arrive according to schedule (more or less), we, of course, cannot assume an exponential distribution for the times between two arrivals. And in a perfect world, buses arrive according to schedule.
However, in my home city, Berlin, it may not be too far off to assume an exponential distribution. Because sometimes I get to the bus stop and I wait for 10 minutes. Then three buses of the same line arrive immediately after one another. Those are the moments where I am convinced that the exponential distribution may not be the worst distribution to choose when modeling this problem.
And next time you’re waiting at a bus stop and running out of small talk — here’s a story to tell.