Measuring Network Centrality
An Intro To Quantifying “Importance” Through Graph Theory


Network analysis sounds like a clandestine, cyberpunk job tasked to only top NSA & Mossad modelers. However, this concept of mathematically dissecting “networks” is far from new; in fact, its logical origins extend back to the times of the eminent Euler (18th century). The branch of math behind network analysis, graph theory, is far from new — yet it’s applications in the digital world are undeniably exciting.
From social media to sociology studies to more traditional networks, graph theory has re-surfaced as network analysis. Graph theory, a discrete mathematics sub-branch, is at the highest level, simply the study of connection between things. These things, which are more formally referred to as vertices, vertexes ornodes, have varying connections between themselves referred to as edges or links. Graphs are visually captivating & are typically displayed like the following:
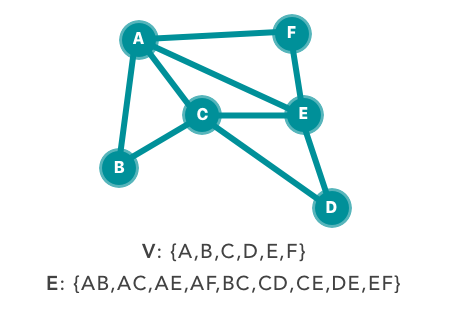
From Graph Theory To Network Analysis
The simple graph laid out above is one of the most basic graphs possible. It’s simple because it’s lacking additional properties. Graphs, like the dynamic systems of objects they represent, take on an unfathomable amount of shapes & sizes; it’s, therefore helpful to create a set of properties to specify unique graph attributes. Let’s quickly review the most common properties encountered in graph theory:
- Undirected vs. Directed Edges
- Unweighted vs. Weighted Edges
- Including/Excluding Multiple Edges & Loops
The clearest & largest form of graph classification begins with the type of edgeswithin a graph. Two main types of edges exist: those with direction, & those without. An undirected graph, like the example simple graph, is a graph composed of undirected edges. In a directed graph, or a digraph, every vertice has a minimum of one incoming edge & one outgoing edge— signifying the strict direction of each edge relative to it’s two connected vertices.
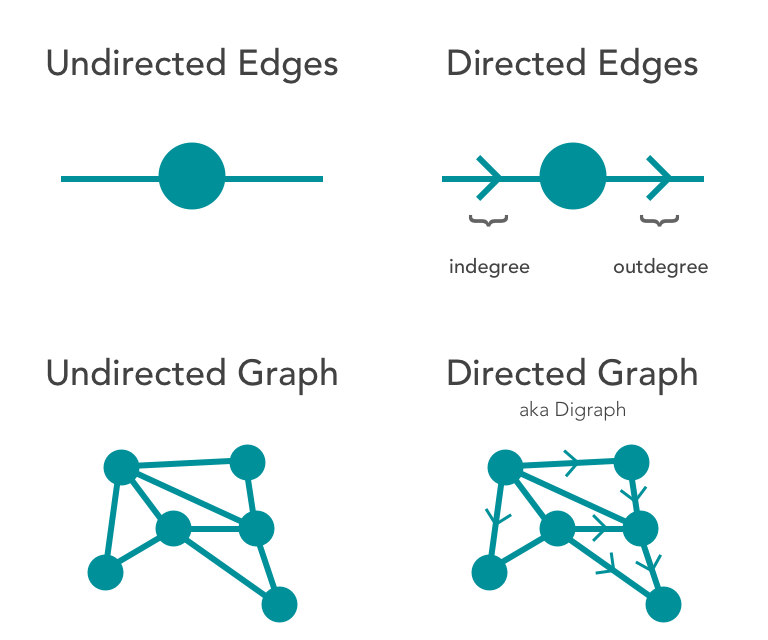
To provide further context to the example above, compare a social media network like Facebook to Medium. On Facebook, there is no direction; regardless of who sent the original request, once accepted, two people are friends. On Medium or Twitter, users can follow another user without that second user reciprocating. The examples below highlight this difference:

We’re driving home this difference because, as we’ll see shortly, they greatly affect how we carry out the main network analysis we’re focusing on today: centrality. For the rest of this article, we’ll be dealing with undirected graphs.
Centrality
In the analysis of graphs, or network analysis, indicators of centrality identify the most “important” nodes within a graph; in other words, how “central” a node is within its parent graph. However, different nodes could be considered important depending on how “importance” is defined. Centrality comes in different flavors & each flavor defines the importance of a node in a different way — which leads to a unique way of measuring centrality. Centrality is often the first measurement introduced to those learning about network analysis due to its wide application. Calculating it can identify the most influential person(s) in a social media, key infrastructure nodes in an intranet network, or even pinpoint super-spreaders of disease.
Centrality algorithms use graph theory to calculate the importance of any given node in a network. They cut through noisy data, revealing parts of the network that need attention — but they all work differently. Below we’ll cover the three most common ways of measuring network centrality:
- Degree Centrality
- Closeness Centrality
- Betweenness Centrality
Centrality indices are answers to the question “What characterizes an important node?” The answer is given in terms of a real-valued function on the vertices of a graph, where the values produced are expected to provide a ranking that identifies the most important nodes. Below, we’ll expand on these three varying measurements one at a time.
Degree Centrality
The first flavor of Centrality we are going to discuss is “Degree Centrality;” it’s by far the simplest & most intuitive measurement. To understand it, let’s first explore the concept of the degree of a node in a graph.
In a non-directed graph, the degree of a node is defined as the number of direct connections a node has with other nodes; how many direct, ‘one hop’ connections each node has to other nodes in the network. Degree centrality assigns a score based simply on the number of links held by each node — the higher the degree of a node, the more important it is in a graph.
The theory behind this is that the more connected a node, the more likely that node is to hold most information or individuals who can quickly connect with the wider network. Mathematically, the Degree Centrality is defined as D(i) for a node “i” as below:
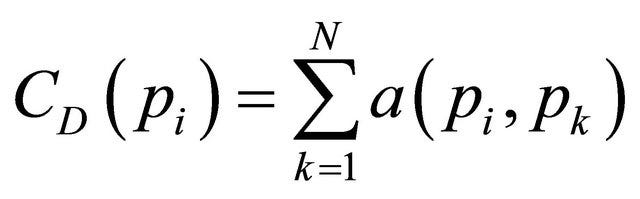
The calculation is easier than the complex notation above implies — for each node, simply count how many other nodes it’s connected to. Not all marketers are mathematically aware of this measurement, yet there’s no doubt that this is the intuition behind common social media marketing strategies such as influencer marketing. This is the answer to the arithmetic why celebrities are paid to say or promote specific products or services.
Closeness Centrality
The second flavor of centrality we’ll discuss is none other than the “Closeness Centrality.” The closeness centrality (or closeness) of a node is a measure of centrality in a network that’s calculated as the normalized average of all of it’s geodesic distances. This measure calculates the shortest paths between all nodes, then assigns each node a score based on its sum of shortest paths. To understand this measurement more deeply, we first need to introduce the previously-undiscussed concept: the “Geodesic distance” between two nodes in a graph.
The Geodesic distance d between two nodes a & b is defined as the number of edges/links between these two nodes on the shortest path(path with minimum number of edges) between them. Mathematically, Geodesic distance can be defined as below:
d(a , b) = No. of edges between a and b on the shortest path from a to b, if a path exists from a to b
d(a , b) = 0, if a = b
d(a , b) = ∞ (Infinity) , if no path exists from a to b
Closeness centrality scores each node based on their ‘closeness’ to all other nodes in the network. Thus, for each node, we’re simply finding the normalized, average geodesic distance to all other nodes. The final formula for the Closeness Centrality (Cc) of a node i in a graph is defined:
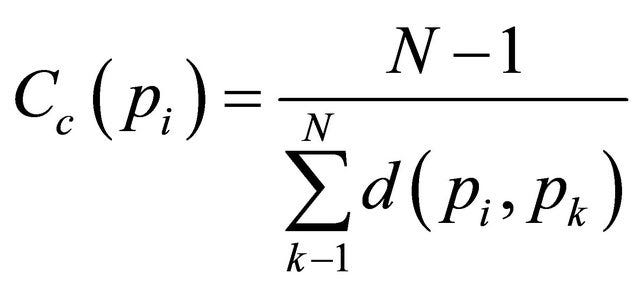
Take a step back — why use this alternate centrality definition at all? Well, because “importance” within a graph, what we’re attempting to capture with measurements of centrality, can mean very different things. Having the most connections in a network, what degree centrality measures, intuitively translates to a power-by-concentration concept; the node with the highest degrees is undeniably powerful. But, what if we cared about power not in terms of concentration, but in terms of information speed? In other words, what if weren’t looking for the most connected node, but rather the node that can spread information the fastest? Surprisingly, the node with the highest degree concentration is rarely seldom the node with the shortest average geodetic distance.
So let’s suppose we want to send a piece of specific information to each node of the graph — we’d need to select a node in the graph that can transmit it quickly to all the nodes in the network. In this particular case, we calculate the closeness centrality as described above; it helps us find the best broadcasters in a given network.
Betweenness centrality
This next measurement of centrality, betweenness centrality, also ties neatly into the concept of geodesic distances. This measure shows which nodes are ‘bridges’ between nodes in a network; it’s calculated by identifying all the shortest paths (the geodesic distances) between all pairs of nodes, & then by counting how many times each node falls on one of these paths. Instead of aggregating the geodesic distance from one node to all others, we’re instead counting the number of times a node shows up in-between the shortest path.
Betweenness centrality measures the number of times a node lies on the shortest path between other nodes; it represents the degree of which nodes stand between each other. Mathematically, Betweenness Centrality B(i) of a node i in a graph is defined as below:
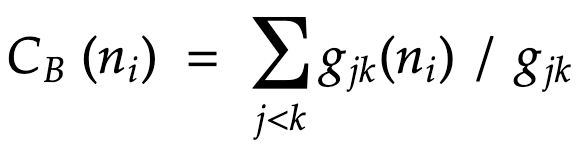
Nodes with high betweenness may have considerable influence within a network not due to their concentration or their transferring speed to other nodes, but rather, by virtue of their control over information passing between other nodes. Conversely, nodes with high betweenness centrality scores are also the ones whose removal from a network will most likely disrupt communications between other nodes.
Referring back to our NSA/Mossad modelers line in the opening paragraph, betweenness centrality has pretty realistic applications. For example, imagine analyzing a network of global terrorists with the goal of maximal disruption. To achieve this, we’d start by removing the node with the highest betweenness centrality. Probably a more relatable example — using this same process can help identify & correct possible bottlenecks in logistic processes.
Both scenarios provide us with insight into the application of this centrality measure. It defines & measures the importance of a node in a network-based upon how many times it occurs in the shortest path between all pairs of nodes in a graph.
In Closing
The field of graph analytics is vast & has immense practical applications. The scope of this article was simply to introduce & cover a fundamental metric of network analysis: centrality. As we’ve seen, this is simple, but not easy, as there are multiple starting points for centrality — this means we have to carefully-consider which is the right type of centrality for each scenario:

Now, we’ll close this piece with a necessary disclaimer that slight caveats exist with each of these indices. Not only is it critical to choose the right type of centrality, but additionally, it’s likely that the node-ranking system that results from each calculation is a bit deceptive. A ranking system is clearly relative to other nodes — which heavily overlooks absolute measurements. Maybe the difference in “importance” between one node & the preceding/following node is insignificant, or perhaps it’s the largest difference in the list of nodes.
Either way, it’s exhilarating to apply math to something as humanly-natural as group dynamics; yet it’s clear that this is just a basic introduction to graph theory. Centrality is but one of many important metrics when analyzing networks.