Let’s Design A Simple Algorithm
From elementary mathematics, we are familiar with the four basic mathematical operations associated with numbers — addition, subtraction…


From elementary mathematics, we are familiar with the four basic mathematical operations associated with numbers — addition, subtraction, multiplication and division. There are many kinds of numbers in mathematics with their own set of unique operations. Here we are concerned about the most commonly used numbers that we deal with everyday, which are technically called “real” numbers — like 43, 14/223, 7.381, 0.001 and so on.
The use of these four operations have been taught to us at a very young age, which makes the use of such operations a trivial task for most of us. It’s possible that a particular calculation involving these operations might be time consuming, but the rules are simple to follow. In particular, we find it quite easy to perform the operations of addition and subtraction even on big numbers. Unfortunately, we cannot say that for multiplication and division operations — they are notoriously hard to understand and execute even for relatively small numbers. In particular, the algorithm of division is arguably much harder to execute than multiplication.
After many centuries of progress, we have developed machines that could perform these operations — first mechanical and then electronic calculators. These machines are remarkably efficient and fast. Electronic calculators are amazingly fast — so fast that we do not stop to think, if these machines use exactly the same algorithms that we learned as kids. In fact, it was (and still is) one of the toughest problems for an engineer to design a machine that performs multiplications and divisions on arbitrarily small or large numbers in a fast and efficient manner.
If we talk about digital computers, division is a particularly tricky operation to design a hardware for. All modern, mainstream CPUs have special hardware blocks to perform division (also multiplication), which are quite sophisticated. But this was not the case for early computers, where they had hardware blocks to perform only additions and subtractions. The operations of multiplication and division were built using software routines on top, using repeated additions and subtractions respectively. Even today, many of the tiny, low powered CPUs still do not have a hardware multiplier and/or divider built into them — simply because these two operations are very resource hungry. So, in case we end up with such restrictive CPUs, which are pretty common in tiny, low powered gadgets like wrist watches (not smartwatches) and cheap pocket calculators, we would need a software based solution.
If we focus our attention on the process of division of a number, b, by another number, a, we can write it as,

This equation shows that the division of two numbers is equivalent to a multiplication of the numerator b with 1/a, which is called the reciprocal of the denominator a. If we are able to find an efficient algorithm for finding reciprocals, we could use the much simpler operation of multiplication, to solve the division problem.
In this article, we will study in detail, a method of finding the reciprocal of a number. There are many ways to do this, but one of the best known methods to solve several kinds of mathematical problems is the Newton’s method (also known as the Newton-Raphson method). It is an iterative method, which provides only an approximate result, up to a desired level of precision. There are times, when one could come up with a clever method of solving a particular problem which might be faster or more efficient than Newton’s method, but for problems when there is no clever way out, Newton’s method is often the best option — it’s basically a really powerful general-purpose method.
For using Newton’s method, we require a good understanding of calculus, which is beyond the scope of this article. Therefore, here we are going to see a non-calculus based method, which is at least as good, and we might be able improved it further.
For a beginner friendly introduction to calculus, check out this article.
Need For An Algorithm
Let us have a look at a few simple known cases. Suppose, we need to evaluate the reciprocal of 5, which we know from the definition to be 1/5 = 0.2. It looks like a fairly straight forward calculation, but the problem comes when the numbers are relatively bigger (or smaller) — for example, what would be the reciprocal of 1178 or 89243752 or an even bigger number? We can follow the rules and obtain the result, but it is not hard to imagine that these kinds of calculations, if performed manually, can sometimes be quite tedious if not too difficult.
The real problem comes, when we choose to do this on a computer system. We tend to write an algorithm exactly like the one we use with pen-and-paper calculations. It’s called the “long division method”, and is not the easiest (and the most efficient) algorithm to learn and use, even for computers.
One of the most intriguing things about humans is that we absolutely hate doing repetitive tasks, and always try to find clever tricks to avoid repetitions. Most of our mathematical methods are driven by the desire to be non-repetitive. It turns out, this is exactly opposite to how computers are designed to work. Computers tend to excel at doing repetitive tasks — in fact, they are so powerful because they are very efficient at doing simple repetitive tasks. This is why it is very hard to write good computer algorithms, because we have to leave behind most of the methods that were optimized for manual calculations, to be done by humans.
So, if we want a method of solving a problem which is optimized for a computer, we must think in terms of small, incremental and repetitive tasks. Such methods are called iterative methods.
If you are liking the story, you might consider subscribing to a newsletter to receive more stories like this, directly in your inbox !
Developing The Algorithm
Let us say that we want the reciprocal of the number a. Now, we may not have an exact result, but we could make an educated guess. Suppose that our first guess is x₁, which may or may not be good, but we can write the following equation,
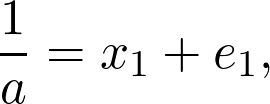
where x₁ is the guess value which should not be too far away from the exact result, and e₁ is the error in the guess. This error could be big if we made a poor guess, or it could be tiny, in case of a good guess. If we are very lucky and our guess is perfect, the error will be zero.
We can rearrange this equation in the following way,

Now, if our first guess, x₁ is sufficiently good, then the error, e₁, will also be sufficiently small (compared to 1). By looking at the equation, it is clear that if the numerator on the left hand side is really small, it would imply that the error, e₁ is also really small. Therefore, we can relate the size of the error with the size of the numerator on the left side.
An important property of (positive) numbers smaller than 1 is that — a multiplication with itself, will result in an even smaller number, as shown below.

We see that squaring a small number, gives us an even smaller number, and perhaps we could use this fact in finding an improved guess by demanding that,
The error in the next guess must be proportional to the square of the error in the previous guess
In mathematical terms, this is written as,
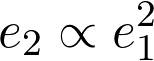
But, according to the discussion above, this is equivalent to the following equation,
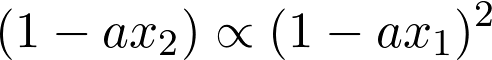
We can remove the proportionality by choosing a constant k, and get,
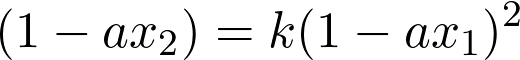
Using basic algebra, we simplify this equation to obtain the value of x₂ as follows,
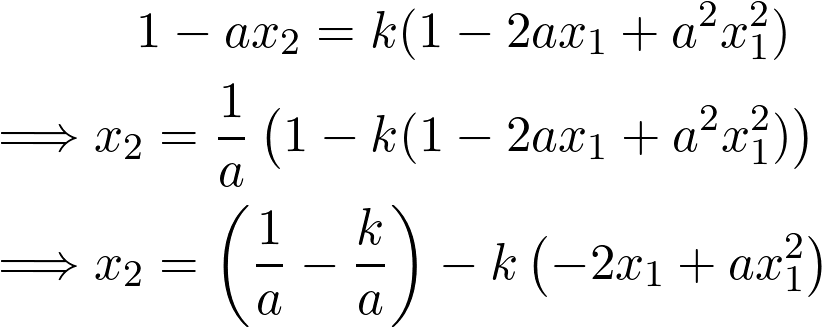
It can be seen from this equation that there is a 1/a term on the right hand side, which is nothing but the reciprocal of a. This doesn’t help because it is exactly what we are looking to find in first place, and is still unknown. It may seem like we are going in circles, but there is a simple way out. If we choose, k=1, then 1/agets canceled, and we don’t have any problems. Therefore, with this choice of k, the previous equation can be written as,
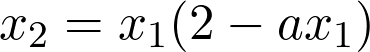
This gives us the second guess to our problem, which should be an improvement over the first guess. We can repeat this exercise, and obtain a third guess, which would be much better than the second, and so on. Instead, we can generalize the equation by writing it as,

This is the master formula that we can use for an iterative process, to find the reciprocal of a number a, by calculating as many successive values of xₙ as we need, till the desired level of precision is reached.
Let us take an example and see how it works. Suppose we want to find the reciprocal of 13, with an initial guess, x₁ = 0.1. The table below shows the first three iterations of the master formula.
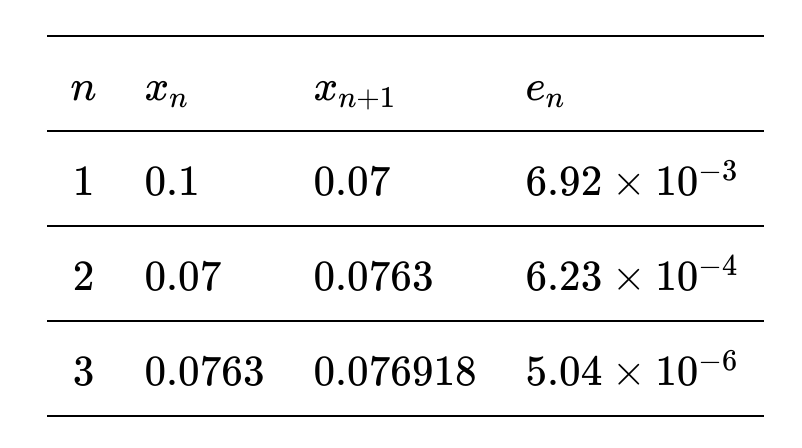
The exact value of 1/13 is 0.076923…. We can see that only after three iterations, we have found a result which is correct up to five decimal places. We can improve the precision as much as we want, by increasing the number of iterations. We also see from the fourth column of the table, that the error is successively getting smaller, which suggests that we are converging towards the correct answer.
Interestingly, the master formula that we have obtained, is exactly the same formula that we would have obtained if we used Newton’s method based on calculus. The formula is compact, efficient and accurate enough to be used in early computers and portable calculators which had very limited computing power, and could be used even today.
The following python code can be used to try out the algorithm for different numbers.
Improving The Algorithm
We already have a pretty good algorithm, and may not require anything more. But, it might be interesting to see if it is possible to improve it further.
The central idea behind the algorithm is that we have used the fact that numbers smaller than 1, get even smaller upon multiplication with themselves. Earlier, we used the squaring or quadratic operation (power of 2) to reduce the successive errors in computation. But, we could have tried the cubic (power of 3) or quartic (power of 4) operations, making the errors even smaller. Let us see if such an algorithm offers any advantage.
If we choose to work with the cubic operation, the equation for errors, would look like the following,
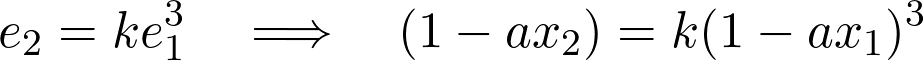
By choosing the value of k=1, and simplifying it further, we will obtain the following master formula,
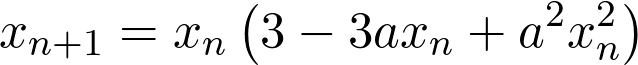
Similarly, for the quartic case, the master formula would be,
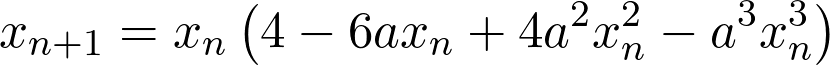
If the reader wants to try out, the python code listed earlier has a few commented lines of code, corresponding to the cubic and quartic algorithms as well.
In the following table, we have shown the successive errors for the quadratic, the cubic, and the quartic algorithms after three iterations, for the case of a=13, with the first guess, x₁ = 0.1
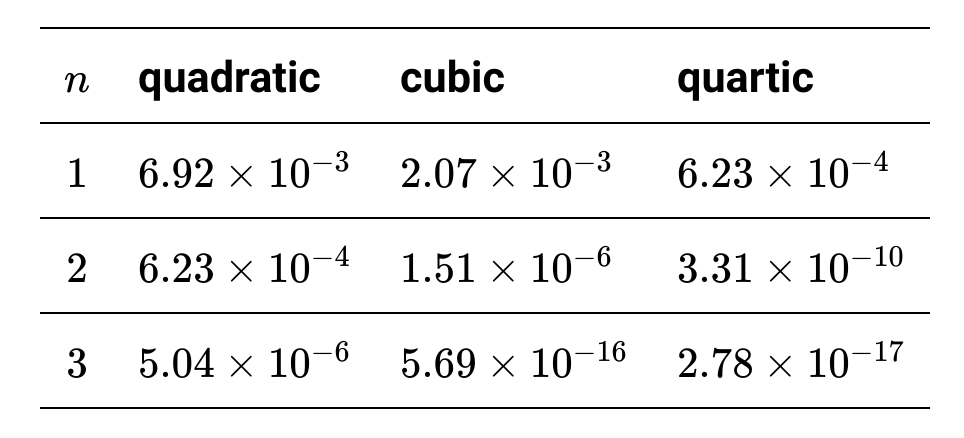
It is clear that if we use the improved algorithms, we can drastically reduce the errors, in the same number of iterations, but at the cost of increasing the complexity of the computation.
Originally published at https://physicsgarage.com on June 15, 2020.