Graphing Erdős and Bacon
Where are you on the networks?


A primary use of social media is networking. Networks are graphs. Work well with someone, and they can recommend you to work with someone else. Your graph of connections grows, and, assuming some regularity conditions in the access your connections have, the probability of better future work increases.
Social media usage is certainly not limited to job-based networking only. We use these platforms to share content through a similar kind of connection graph, be it academic colleagues, friends, relatives, loved ones, and so on. These are the same kinds of graphs, semantically: vertices are people, and edges are the semantic connection between them. The semantic connection between two vertices on this kind of graph could be “worked with” (collaboration graphs), “is friends with” (social graph), “is related to by blood” (ancestry graph), etc.
As they share “person” as the primary vertex type, these graphs can intersect to yield richer, more semantic understanding of our connections to each other. Beyond the person-only vertex, we can add vertices representing workplaces, event spaces, schools, hangouts, academic papers, books, films, games, software, foods, meme categories, ideas… any thing with which we can build a semantic connection to and from another person.
“Six degrees of separation”

The 1929 short story “Chain-Links”, by the Hungarian author Frigyes Karinthy, is the commonly-recognized first published description of what is now known as “six degrees of separation”. In the story, the narrator describes a game of connecting any two people on the planet via a chain of semantic connections.
One of us suggested performing the following experiment to prove that the population of the Earth is closer together now than they have ever been before. We should select any person from the 1.5 billion inhabitants of the Earth — anyone, anywhere at all. He bet us that, using no more than five individuals, one of whom is a personal acquaintance, he could contact the selected individual using nothing except the network of personal acquaintances.
The narrator and his friends begin with a “simple” connection using famous people, and then move on to more “average” human circumstances.
I proposed a more difficult problem: to find a chain of contacts linking myself with an anonymous riveter at the Ford Motor Company — and I accomplished it in four steps.
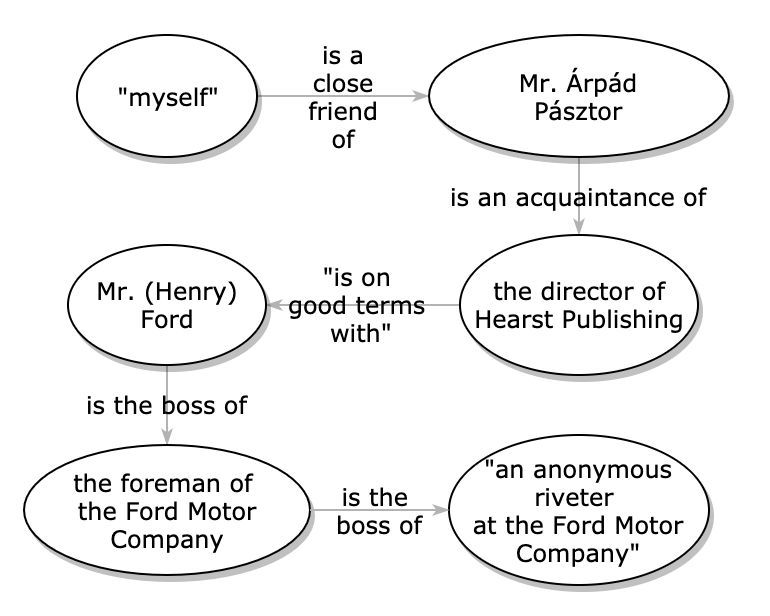
The idea that this is even possible in society only makes sense in what Karinthy, and later such social critics as David Harvey (The Condition of Postmodernity), describe as a “shrinking” of the world via the technologies of high-speed transportation, synchronous timekeeping, and wireless communication. In the distant past, this “world shrinkage” was not physically possible; only in this (post)modern world, it is argued, would all people be connected.
It is due to this shrinkage of time with respect to communication that we are able to abstract the notion of “distance” as a physical property, and consider it mathematically.
An uncheckable social “distance”, however, allows these social connections to be exploited. A Pulitzer- and Tony-nominated play called “Six Degrees of Separation” was written by John Guare in 1990, which was soon after made into a feature film. The story, based on a true story from the 1980s about a con man claiming to be Sidney Poitier’s son, involves a scam artist using the strong social connectivity of high-society New York City to run scams based on false information about his own place on the social graph.
The mathematics of networking
Another pair of famous Hungarians (that we’ve met before in this virtual space) share the spotlight with Karinthy on the development of the stochastic connections we can make in life. Paul Erdős and Alfréd Rényi introduced the aptly-named Erdős-Rényi model of random graph construction in 1959 to use with their new combinatorial proof technique, the probabilistic method, in proving theorems on the existence of certain kinds of graphs.
With our current computing technology and interests, this type of modeling can be used in tandem with Monte Carlo simulation to analyze networks.
Aside from graph theoretic analysis, there are clear reasons why we would care about such structures of data connecting people. The entire existence of such social networking sites as Facebook (with one original semantic link: “is a friend of”) and Twitter (which began with the directed semantic connection of “follows” or “is followed by”). Google’s PageRank algorithm relies on the similarly-paired semantic connections “links to” and “is linked to by”.
As we opened with workplace connections, it makes sense to mention LinkedIn, which is effectively a Facebook clone for business connections, where the semantic reason one may be linked is “worked with”, “is a headhunter for”, or “is a friend that’s just helping with connectivity”.
All of these social and collaboration connectivity graphs have something mathematical in common — the emergent property known as the “small world phenomenon”. This phenomenon, which describes the relative connectivity of nodes in small clusters, which are themselves in small clusters, can be modeled in the more recent random graph modality named after Duncan Watts and Steven Strogatz in 1998. Using both the probabilistic method and the Watts-Strogatz model, we can understand small world-type graph structures analytically and probabilistically.
The networking of mathematics
I’m interested in examining the human connections made in mathematics as a field. There are multiple collaboration graphs that are well-established, and constantly growing, in the world of mathematics; here are three of the main ones, none of which is by any means complete.
Mathematics Genealogy Project
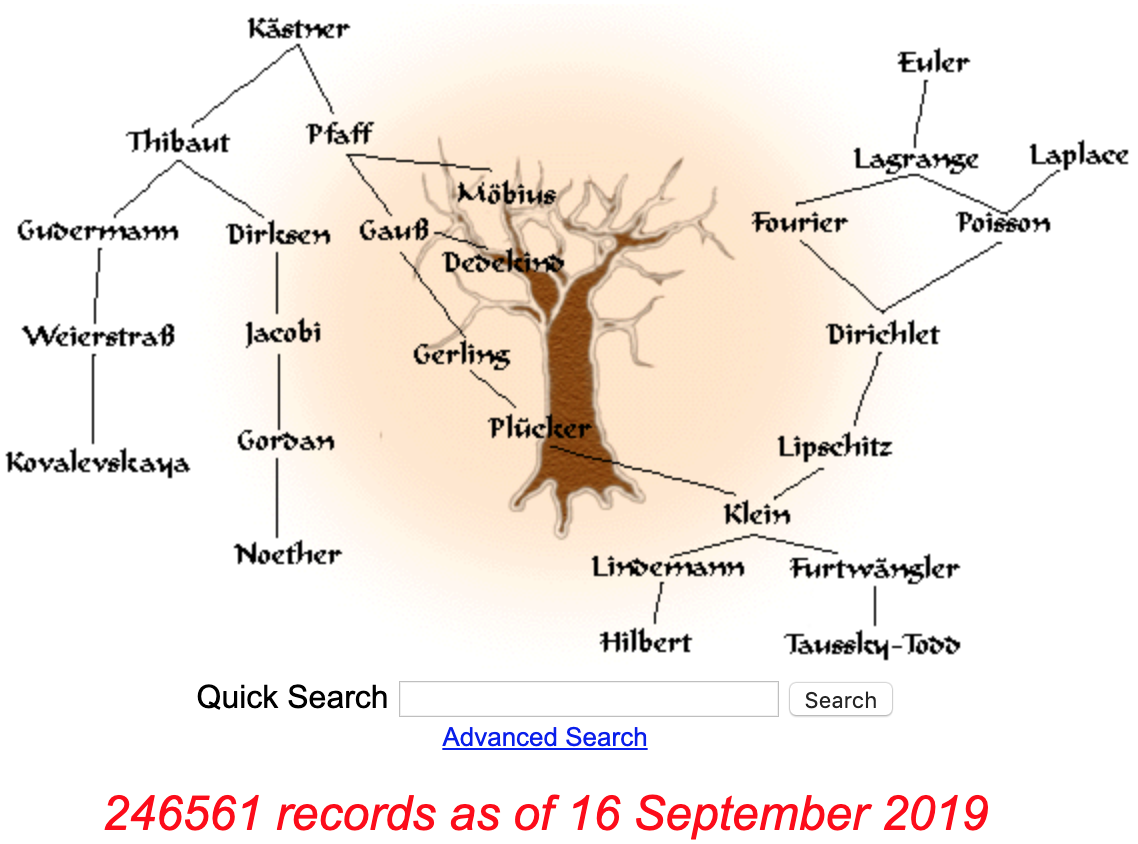
The Mathematics Genealogy Project is an ancestry graph of a kind, tracking the mathematical lineage (from dissertation advisor-parent to student-child) of nearly a quarter of a million mathematicians, physicists, and other doctoral-level scientists over the past 900 years (Leonardo da Vinci is in there, as is Gregory Chioniadis, whose dissertation date is 1296, and who has 4 generations of advisors before him without dissertation dates).
The MGP has metadata for several databases, providing a rich semantic connectivity to a mathematician’s knowledge of their colleagues. Depending on the fame of the subject, they may have links to or information about:
- MacTutor History of Mathematics (biography)
- MathSciNet (publication history)
- PhD institution and year
- dissertation advisor
- PhD students of whom they acted as dissertation advisor

Recently, the American Astronomical Society has attempted to get their own version of the MGP up and running for astronomers, called AstroGen. While it is not currently public-facing, we’re eagerly awaiting another lineage-based academic ancestry graph.
(If you know of any other academic genealogy projects like this, please tell me and I’ll add them here.)
zbMATH
zbMATH exists primarily to post reviews and abstracts of mathematical papers. Its vast collaboration database, gleaned from over 4 million documents, contains a collaboration graph of over 1 million authors, dwarfing the “person” content of the MGP.
While there is access to several sources of open-source journals, what we are interested in here is collaboration data, and this is unfortunately locked into zbMATH and Springer Nature’s system, with access to only 3 document results per author without an institutional subscription.
MathSciNet
MathSciNet, hosted by the American Mathematical Society, holds several points of mathematics collaboration data, centered on American mathematics. Most of it (primarily, Mathematical Reviews, the AMS journal of, you guessed it, reviews of mathematical papers and books) is licensed to institutional libraries, and so is mostly inaccessible to the public in a simple fashion.

Erdős number
The Erdős number is the shortest distance, small world network-wise, between a mathematician and Paul Erdős on the mathematics authorship collaboration graph with semantic connection “has co-authored a paper, book, book chapter, monograph, etc. with”. As Erdős has over 1500 publications to his name, a legendary collaboration record, and a fantastic backstory, he has become synonymous with “being a mathematician”, according to this metric. The closer you are to Erdős on the collaboration graph, the logic goes, the closer you are, academically, to greatness.
If you authored a paper with Erdős, the path between you and him is two edges long, with one “publication” vertex between you. Hence, your distance to him on the graph, and number, is Erdős-1. If you had no papers with Erdős, but a paper with someone who did, you are Erdős-2. And so on out. (The smaller the number, the “better”.)
Contrariwise, if it was so that you had no papers connecting to Erdős at all (technically meaning you’re on a separate component of the graph — the mathematics collaboration graph is disconnected!), your Erdős number is infinite, as there is no collaboration-wise path between you and Erdős.
According to the Erdős Number Project, there are 511 people with Erdős-1.
There will likely never be another, as Erdős died in 1996.
Unfortunately, there is no complete mathematics collaboration graph. zbMATHand MathSciNet offer free collaboration graph searches (defaulting to Erdős) on their sites; you need to be looking at an author on zbMATH. Thus, anyone interested in computing their Erdős number must check both of these sites (in case of a lack of publication overlap between databases), plus any verifiable publication data elsewhere, and take the minimum Erdős number from those three searches.
I am Erdős-5.
I wanted to compute my Erdős number. As zbMATH has not listed all of my publications, according to them I have Erdős-∞.
Sigh.
MathSciNet, however, complete with links to Mathematical Reviews, lists a publication that puts me on the Erdős component.
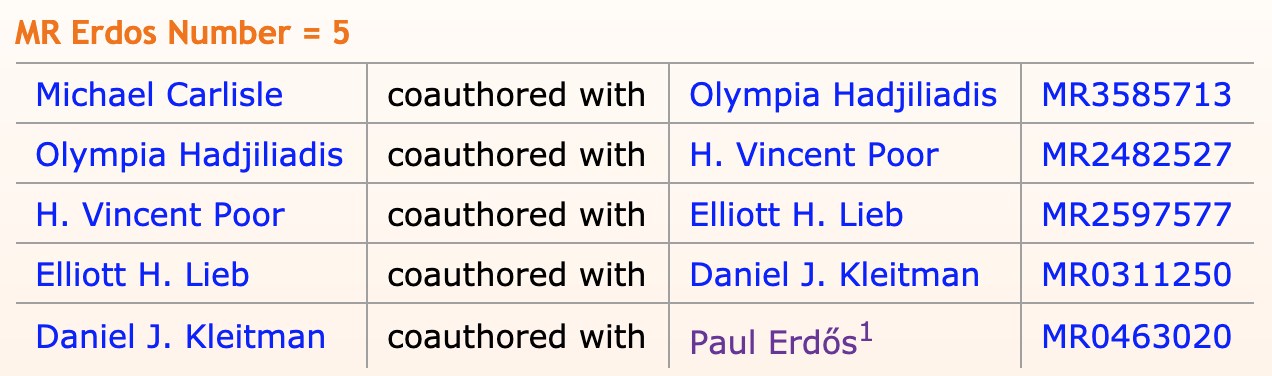
But is that enough? No way.
Polymaths: Unions of Collaboration Graphs
We’ve just witnessed the need for a union of collaboration graphs, as some datasets do not contain a complete picture of the collaborations they purport to describe, and need supplementary data for a more accurate view.
What, then, when we wish to enhance the number of semantic connections between the vertices on a collaboration graph?
Interesting data will come from the intersection of these graphs; who happens to be connected to the “bright nodes” on many of the graphs we’ve merged?
We’ll examine one other collaboration graph, with its own candidate for most-popularly-connected: appearance as an actor in a film, and Kevin Bacon.
Film collaboration: Bacon numbers
Consider the collaboration graph with semantic connection “acted in (a movie) with”. On that graph, Kevin Bacon is one of the simultaneously most well-connected and well-recognized vertices, and so has earned a cultural parallel with Erdős in the so-called “Bacon number”. (There is, of course, some dispute as to whether Mr. Bacon should be considered for this role as “center of the Hollywood universe”, instead of, say, Samuel L. Jackson.)
The IMDb is the primary source for collaboration data on film and TV interactions for human and industry perusal; however, the vast amount of unlisted feature and short films make the external-to-IMDb data collection a more challenging problem, unless you know where you’re looking. Film festivals posting shorts to YouTube and Vimeo is a good starting place, for those interested in investigating.
There are more difficulties in computing an actor’s Bacon number than a mathematician’s Erdős number, due to the fact that there is only one real source for direct computation: the Oracle of Bacon, which scrapes Wikipedia for actor data. While this is hardly IMDb-level data, it makes some of the basic connections for us.
I had to give it a try. On myself.
I am Bacon-3.
Wait, what?
Why do I care about my Bacon number? Because we’re talking about multiple collaboration graphs here! If I happen to have a film credit somewhere, no matter how small, then there exists an intersection of the mathematics world and the film world where I am one of the few connected to both of these figures.
I happened to appear in a short film on the NYC circuit a couple years ago, which is still moving around short film festivals. (Yes, I “acted”, and I’m also listed as “caterer” because I brought beer to m̶y̶ ̶f̶r̶i̶e̶n̶d̶ ̶t̶h̶e̶ ̶d̶i̶r̶e̶c̶t̶o̶r̶’̶s̶ ̶a̶p̶a̶r̶t̶m̶e̶n̶t̶ the set.) Now, this film is not in the IMDb (as of this writing), but does have a public record and awards, so it counts.
Starring in this short film is a professional actor named Jared Johnston. While not Wikipedia-listed, and so does not appear in the Oracle of Bacon, Jared does in fact have a Bacon number — Bacon-2.
How do we know? We scrape Jared’s IMDb page and spider through the connected films, building a small portion of the collaboration graph, until we hit Kevin Bacon, then filter the results down to what we need. Minimal fuss.

And that’s all it took. Jared is Bacon-2, and so I, and all my co-stars, are Bacon-3. As simple as that.
Aggregate Metrics of Cross-Industry Collaboration
Summing the two collaborative measures yields the cross-industry collaboration metric known as the Erdős-Bacon number, which may indicate reach across disparate fields of interest. (Or, in my case, agreeing to silly things at just the right time. And bringing booze.)
My Erdős-Bacon number, as it stands, is 5+3 = 8.
Here is Wikipedia’s current (incomplete) table of well-known finite Erdős-Bacon numbers:
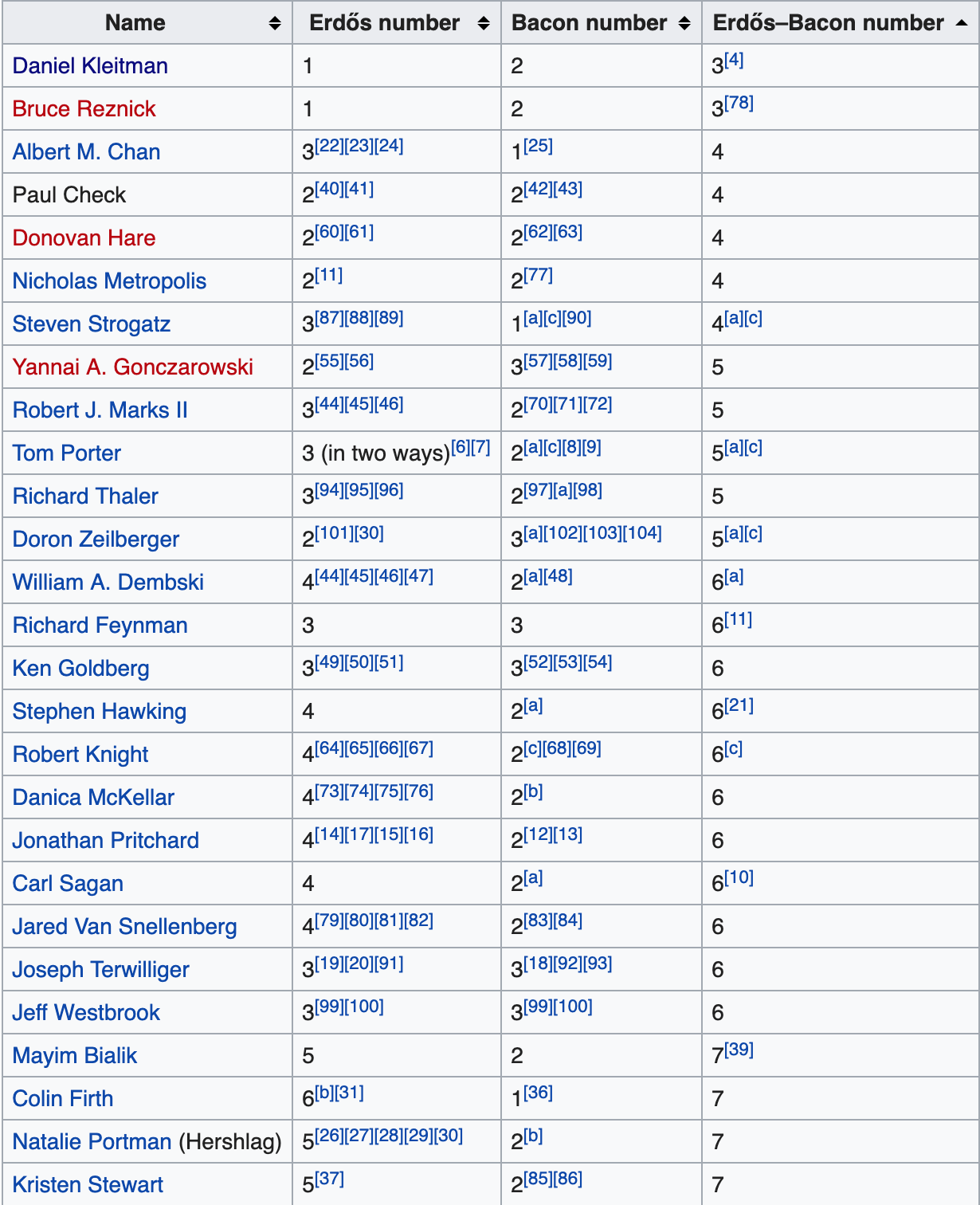
Is this enough? Nah. Cross-collaboration can always reach more fields. You see, there’s also a thing called the Erdős-Bacon-Sabbath number. Yes, that Black Sabbath.
A brief question about the metric
At this point I will declare myself an outlier by being on this graph intersection — not being a film industry insider, and no longer a mathematical industry insider, the simple graph-based metric used here seems to inflate my importance relative to the people listed on Wikipedia.
I’m not talking myself down; you can’t pry this finite value out of my cold, dead hands. But I am questioning the usefulness of the metric. Is this number a statement of “collaboration existence”? (Yes.) Can the metric be construed as a measure of influence in both industries? (No.)
I would propose, as those immersed in the worlds of feature films or feature construction, selection, and elimination are concerned, a more computationally-refined metric on top of the existence metric just presented, that takes into account the richness of connectivity of a person with their collaborators, the time frame involved, current activity, etc.
Let’s call this proposed metric “Erdős-Bacon influence”.
Applications to other fields of inquiry
Other fields of inquiry are certainly interested in cross-industry collaboration and influence. There is a cross-collaboration potential of scraping medical research publication data and cross-referencing it with clinical trials, medical research Twitter, grant applications, and historical institutional data, to develop profiles of “influencers” in medical research, and detect if and when their subject matters show the potential of creating new medical innovations.
This same idea can be approached in the mathematical sciences. We have access to publications, institutional lineage, social media, and grant data in mathematics. In addition, we have the conceptual content of many of these mathematics papers in somewhat quantifiable packets (definitions, theorems), for reproduction on sites such as Wikipedia, PlanetMath, Wolfram MathWorld, the Encyclopedia of Mathematics Wiki, ProofWiki, and the Stanford Encyclopedia of Philosophy. In this way, it is possible (with enough scraping and massaging) to develop a concept collaboration graph (call it, say, the MathGraph), in which mathematical concepts are semantically linked to their creators’ lineages, and tracked as they develop via generalization and emigration into other fields of mathematics.
By collecting this data locally, one may be able to fully harness modern computational power to develop such “influence” metrics (as, I’m quite sure, Google, Facebook, Instagram, and dozens of advertising agencies and saavy political campaigns have done in the past decade), to better understand not only the past of one’s collaborations, but the potential of their future ones.