Generative AI: A Key to Machine Intelligence?
We’re living in the age of the next industrial revolution: the very first three had freed most of the humans from the hard handwork labor…


We’re living in the age of the next industrial revolution: the very first three freed most of the humans from hard labor. This one is aiming to take us over the last domain of human dominance on this planet: our intelligence. In this article, we will put aside ethical, political and social effects of such revolution and concentrate a bit more on the technical side of it. What we see in media today looks a bit different from the real dominance of machines over humans… or not?
Generative AI == Hyped AI
The most rapidly growing areas of artificial intelligence in the few last years have been computer vision, natural language processing, speech processing and, of course, different customer analytics applications like recommender systems (you may not like it, but targeted advertisements are accurate enough to grow companies’ revenues). What is supposed to be a demonstration of the state of the art performance in every one of these areas? Almost in all these areas, we are surprised by things like DeepFakes videos, realistically generated images of faces, artificial voice records that sound like real ones and, of course, fake news generating Transformers from OpenAI.
A very reasonable question you may ask is
But what all these deep fakes and text generation have to do with intelligence? Is that creativity?
No, it’s just some complicated non-linear statistics.
Can it replace artists, writers or analysts?
Not really, they aren’t even really very helpful at the moment.
Don’t we have more important problems than generating cats in high-resolution, “undress” people in photos and making Mark Zuckerberg saying ridiculous things? Then why is so much time and money of the brightest minds and the most powerful companies are spent on it? To answer this set of questions we need to dive deeper into machine learning basics, in particular, what happens inside of these models, like neural networks, when they are training to solve problems we teach them to do. If you’re interested in the topic, I also recommend you to read the article of mine on other alternative use cases of generative models. And… a motivational quote for today:
If I can’t create something I don’t understand it — Richard Feynman
How “normal” machine learning algorithms work
Let’s have a look at what modern machine learning algorithms can do apart of generating things. Mostly AI applications look like the following:
- Given ECG record, predict if arrhythmia happened on it or no;
- Based on the market trades history to forecast the price movement in the future;
- From the history of movie views of yours and your friends to recommend a movie to watch.
In mathematical terms, we have a function with a lots of degrees of freedom (lately such functions are deep neural networks) that, with correctly found these degrees of freedom (or weights, or parameters) are able to map complex input data (images, text, sounds, statistics) to some defined outputs, that can be sets of categories, real values, or even really complex structured outputs like graphs.
How to find correct parameters? Usually, we define some criteria of goodness to maximize (for instance, the accuracy of classification), its mathematical surrogate (like cross-entropy, also called loss function) and having a differentiable data modeling function and differentiable loss function we can run numerical optimization process, that maximizes performance of a model on empirical observations with respect to the degrees of freedom.
At the end of the optimization process, if you have big enough dataset of inputs and corresponding correct outputs and you have chosen good data modeling function, the found parameters will be able to map images of, let’s say, lungs x-ray images to corresponding health state categories. Often even better than the humans do. The key result of all the training process is, of course, the set of parameters that supposed to be optimal for some particular problem on some particular data. But is it optimal in general?
Possible biases in supervised learning
We already know that supervised models can perform extremely well on numerous tasks but the outstanding accuracy has its own price. Nevertheless, AI researches do a great job in creating more and more powerful mathematical models, the ones who are feeding these models often misuse them horribly or these models even aren’t meant to meet the expectations.
Overfitting
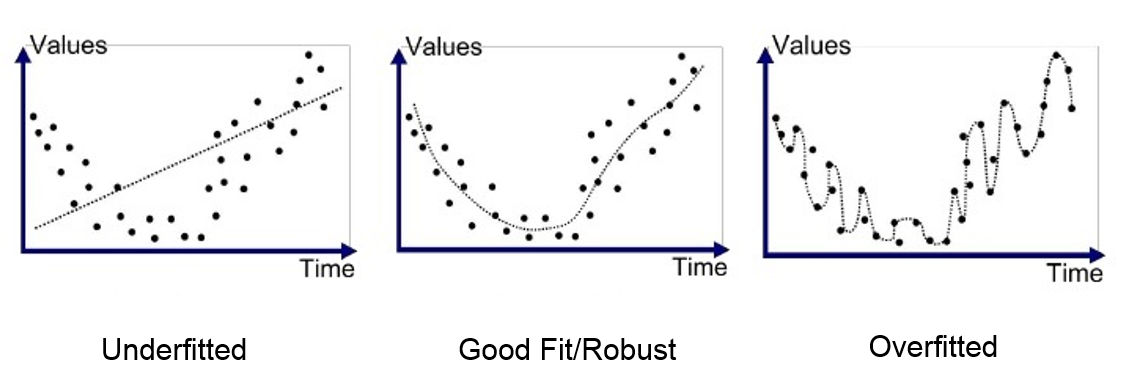
Overfitting has many faces, mainly in practice we’re considering 3 possible situations:
- A weakly regularized model just remembers training data and doesn’t generalize to live data
- We have not enough labeled samples for training the model, so again, we don’t generalize to the live data
- Labeled samples from the training and validation data are totally different from testing data, that’s why, again, performance on the live data shrinks
Mathematically it all means that our parameters w are not capable to describe the patterns in the data apart from the training set.
Human bias

With total adoption of machine learning models by many businesses, a lot of so-called human biases in decision making related to sexism, racism, chauvinismand other negative patterns came up, which can literally ruin other people’s lives, see a great example by the link under the picture above. Well, what we could expect from the algorithms that learn from our past?
Mathematically it means that parameters w are affected not by the nature of the data and true properties, but by the feedback y first of all, which might be biased.
Model bias
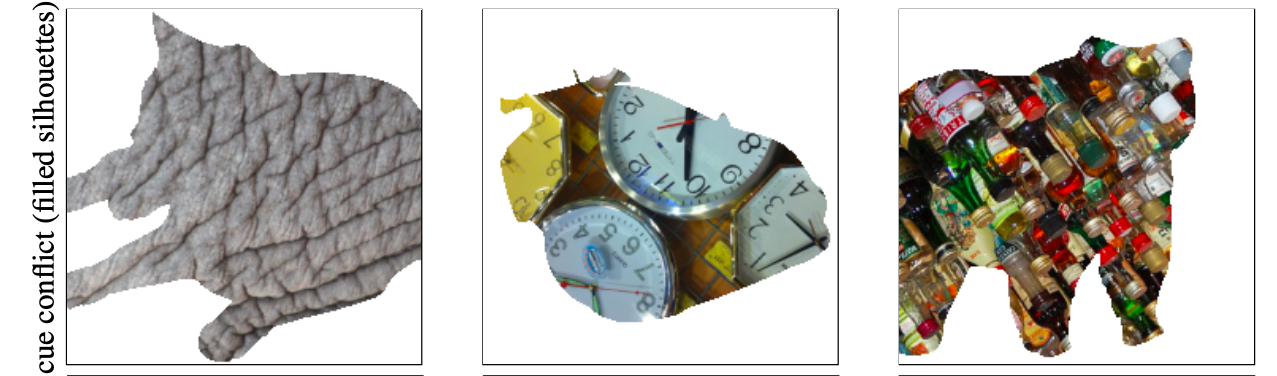
Algorithms that work well in research phase can fail on totally unexpected problems. For example, it turned out that widely used today convolutional neural networks (CNNs) are suffering from adversarial attacks and tend to learn not the shape of the visual objects, but rather their texture (picture and the link above). The problem, probably, lies in the core mathematical operationchosen for the model — convolutions, that are not robust enough as they seem like.

Another example can be reinforcement learning of agents, that supposed to perform the same well in different environments with the same goals and objectives, but they fail, when you substitute, let’s say, the orange ball you have to eat with a blue square. It can be considered as overfitting, but the heart of the problem is in the design of the algorithm as well.
Mathematically it means, that vector w is built not correctly from the structure of the network first of all.
As we can see, most of the problem is diagnosed by some problems in the parameters of the model, their values and their structure. In most the cases, “adding more (correct) data” rule and training on more labeled data with problematic situations (like for Tesla Autopilot) works, but lately some quasi-generative approaches are also popular, as fine-tuning pre-trained models on other, bigger datasets, but probably different tasks. In reality, this is just a hot-fix. Why? Because with literally every new unseen subcase you need to retrain your algorithm, which is not exactly how do we expect machine intelligence to function. If we have a hypothetical app that distinguishes cats from dogs on the images we don’t want to retrain it with every new unseen breed of animal, but to infer the decision somehow from already seen other breeds of cats or dogs.
A historical look at statistical learning
For completeness of the picture, let’s have a look at how machine learning is defined in some rather classical ML books like “Pattern recognition and machine learning” by Christopher Bishop. The author shows modeling pipeline as three high-level options by decreasing complexity:
- First, learn the conditional data-generating model and after applying Bayes’ theorem to model posterior class probabilities;
- Learn posterior class probabilities directly and after hard-code decision theory for classification;
- Find a discriminative function f(x) that outputs classes of x directly.
As we can see, all modern deep learning is about the latter option, which is the easiest and the most superficial one. But the main problem with the fully Bayesian approach is that it can’t be applied to high-dimensional complex data directly at the moment.
What happens inside a generative neural network?
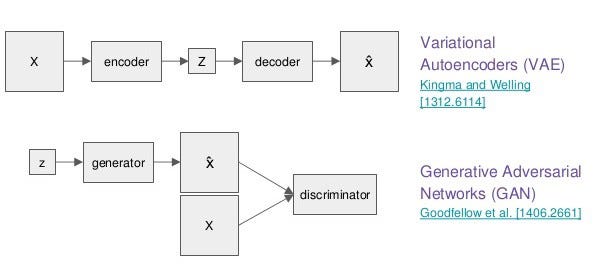
Since we agree, that the straightforward supervised learning might be not the most optimal paradigm to learn effective and generalized representations and we have checked Bayesian approach that is sort of related to generative modeling on its first stage, let’s check main algorithms for generative modeling today and discuss why they are much more powerful tools in the data scientists’ arsenal. We will review generative adversarial networks (GANs) and variational autoencoders (VAEs) as the most popular and as the ones that show the most prominent results lately.
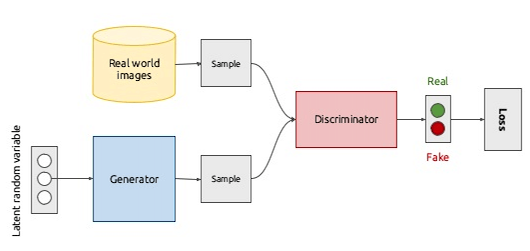
Generative adversarial networks
GANs are neural network-based architectures, that consist of two models: one is called generator G (or sometimes, artist) and second discriminator D(or critic). As you might guess, the generator is a part that is responsible for generating the objects and discriminator is the model that tells if generated by the latter sample looks like real or no. Both networks are being trained jointly together, where the generator is being penalized by discriminator for creating not realistic enough samples. Practical results are indeed astonishing, but digging into representation for later re-use is not that straightforward: we will see it in the next chapter.
Variational autoencoders
VAEs are relatively easier models, even they also consist of two neural networks. The first one (encoder) is trained to encode the input into some compressed code and the second one (decoder) — reconstruct the initial input from this code. The idea is that this compressed representation if chosen and trained correctly can contain all the needed information from the input while having a much lower dimension. We are sure, that this code is sufficient enough if the input can be actually reconstructed from it via decoder neural network. Also, if we sample this code from some distribution, we can generate new realistic samples of data with a decoder from the random code. There are also approaches related to how to control this code and particular propertiesassociated with an element of the code.
Generative learning + supervised learning
Both in GANs and VAEs we can obtain a representation of data (or a code) that can be used for generating realistic objects based on a dataset using some decoder or generator model. But how do we use it for classification, regression and other downstream tasks we’re actually interested in?
Combining discriminative and generative modeling
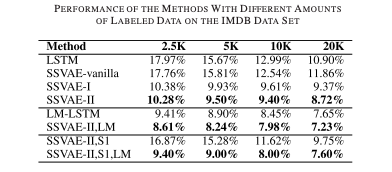
Using VAEs for inference tasks is relatively straightforward — having one, trained in an unsupervised way on a lot of data, we can use the trained encoder to extract features (a code of an object) and over this code train another algorithm from linear regression to another neural network. In this article on semi-supervised text classification you can see how VAEs perform better while having much less labeled data for training:
GANs are a bit more tricky to use since they don’t generate a representation explicitly as VAEs. Usually, the discriminator is leveraged not just to distinguish fake samples from the real ones, but also to solve downstream tasks. Because of “seeing” many real and fake examples it will be automatically more robust than just a supervised model itself. One of the big results was done in remote sensing image classification:
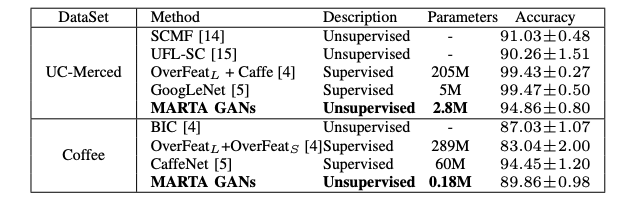
with following-up research with even increased accuracy but still having much fewer complexity and data needed. The coolest part is that in both cases you can train generation and classification jointly rather than one-by-one —usually, it even improves performance.
Fixing supervised learning
Okay, this all is nice, but how do we know that these models can learn representations and extract features that are actually solving issues with classical supervised learning settings and offer us new opportunities and ways of generalization?
- Overfitting: generative models usually have fewer parameters, so it’s harder to overfit, also, they have “seen” more data because of training process based on sampling from the latent space which makes them more robust to occlusions.
- Human bias: in the case of generative modeling, we don’t learn from human labels at all, but from the data properties itself, which allows avoiding spurious correlations.
- Model bias: fewer parameters and ability to generate objects will make such “shape vs texture” issues vanish aways because generative models will never generate samples not similar to ones in the training data.
- Interpretable representation: with techniques as disentangled representation learning, we can make the representation from the latent space clear and interpretable.
- Better decision making: sampling at the core of the models allows uncertainty modeling which can consequently allow rejecting option and, hence, more accurate use of the models.
Generative learning > supervised learning?
Maybe now generative models start looking to you as nice, more complete extension of standard statistical learning framework, that supposed to learn more general knowledge about the underlying data. So why no one is doing that? Why most of the university courses, MOOCs and tutorials are full of supervised learning and unsupervised generative modeling appears only on the blogs of some Ph.D. students and academic publications? It turns out, there are already dozens of cases and I’d like to share some of them to start and after you can easily google much more of them.
- Transformers: neural networks, that are trained to generate texts from huge datasets; it allows them to understand the language first, and only after learning some classification tasks. Currently state of the art in NLP.
- Biometrical face identification: face recognition and identification in the wild is difficult due to different cameras, light conditions, facial angles, ages, skin color, and many other factors. Generative modeling of face images helps to overcome some of these issues.
- Autonomous driving: “…crowd-sourced steering does not sound as appealing as automated driving” ©, check out slides from this workshop to see how self-supervised learning from video helps for building better self-driving vehicles.
- Speech recognition: generative pretraining of voice recognition modelshelps in performance too, as an analogy to text analysis.
- Robotics control: it’s hard to learn robots in real life, that’s why most of the algorithms are developed and tested in simulation… but they fail in real life. Generative modeling with emphasis to domain adaptation helps reinforcement learning algorithms to have better models that understand more abstract concepts both in simulation and the real world.
- Disentanglement and interpretation: last but not least, generative modeling allows us to open up “black-box” neural networks, investigate the inner representations and control them.
Next frontiers
I don’t expect that this short essay already convinced you to stop ever doing supervised learning and rely just on autoencoders for feature extraction for all problems you’ll encounter. The real goal was to broaden the data science mindset a bit, to remind you about the fundamentals of statistical learning and to show, why the AI research community is partly obsessed with generative modeling and it’s not just for amusement.
Also, I recommend you to read the article of mine on other alternative use cases of generative models where I show uses cases beyond supervised learning.
I assume, that you might want to try out generative modeling for good by yourself. I think the best way to start is to take your favorite supervised learning pipeline, train the model to generate realistic samples of your data (convolutional VAEs if images, autoregressive transformers if the text for example) and after finetuning supervised task on smaller subset than you used to work with. Results will be surprising, I am sure :)
For the final motivation, here are examples of unsupervised / self-supervised or generative models that are trying to solve some problems not just on the human level, but totally beyond it and which is almost impossible or senseless within supervised learning paradigm!
- Unpaired translation: what if you could learn how to translate from one language to another without having paired words or texts vocabularies?
- Depth prediction without sensors: what if you could learn physical properties and depth not from LIDARs, but just from pixels?
- Drugs discovery: what if you can create drugs totally automatically without waiting for years?
- Curiosity-driven RL: what if you could train RL agents without even having a reward, which might be too complex and biased by humans?
Stay tuned!