Factorials and How to Compute Them
I am sure you all remember the surprise you had the first time you saw a “5!” or “7!”


I am sure you all remember the surprise you had the first time you saw a “5!” or “7!”, that exclamation mark, and the realization that this was formal mathematical notation…
We define the factorial of a positive integer number n, denoted as n!, to be the product of all integer numbers from 1 to n. More formally, for any positive integer n ≥ 1, we have
n! = 1 * 2 * … * n.
Conventionally, we also define 0! = 1.
For example, we have:
- 0! = 1
- 1! = 1
- 2! = 1 * 2 = 2
- 3! = 1 * 2 * 3 = 6
- 4! = 1 * 2 * 3 * 4 = 24
- 5! = 1 * 2 * 3 * 4 * 5 = 120.
By observing the above expressions, we see that for any positive integer n ≥ 1, we have that
n! = n * (n-1)!.
In words, we just gave a recursive definition of the factorial function. Combined with the base case of 0! = 1, this is an equivalent definition of the factorial of a number.
The two equivalent definitions already suggest algorithms for computing the factorial of any number n, as they are constructive. Moreover, the algorithms implied by the definitions are very straightforward and easy to implement. So, one might, reasonably, ask whether we are done.
The goal of this article is to discuss the task of computing the factorial of a number, which seems so simple and self-explanatory that a lot of people might have never bothered thinking about.
Note: When analyzing the running time of algorithms whose main tasks are elementary operations between numbers, we have to be slightly careful in order not to oversimplify the computational model under which we analyze such algorithms. It is often the case that we assume simple models where each operation (addition, multiplication) takes 1 unit of time to complete, and then the main part of the analysis is to count the number of steps needed. This is extremely useful when it comes to graph algorithms, for example, where the number of steps is the bottleneck of the algorithm. A standard such model is the Random-access Machine (RAM) model of computation. In most cases, this works just fine. But, we should not abuse such simplifications. If we are dealing with numerical algorithms, as we do here, it is often much more meaningful to keep track of the actual size of the representation of a number, and take into account the time needed to perform each elementary operation. And this is what we will do here.
Before actually posing the question of the running time of the algorithms that we have for computing n!, let’s first think about the following question.
Given a positive integer n ≥ 0, how many bits are required to write down (in binary format) the number n! ?
We know that the number of bits needed to write down any positive integer number is equal to the logarithm with base 2 of that number (of course, if the logarithm of a number is not an integer, we have to round up the logarithm to the next integer, but this is inconsequential). So, the number of bits needed to describe n! is (essentially) log n!. We will now estimate log n! up to constant factors. For reasons that will become clear later, we assume from now on that n ≥ 64; this is without loss of generality, as 64 is a constant, and thus, for smaller values of n, we simply need constant space and time to compute the corresponding factorial.
We have
log n! = log (1 * 2 * … * n) = log 1 + log 2 + … + log n ≤ n * log n.
Moreover, we have
log n! ≥ log (n div 2) + log ((n div 2) + 1) + … + log n,
where n div 2 denotes the quotient of the integer division. We now claim that
log (n div 2) + log ((n div 2) + 1) + … + log n ≥ (n/3) * log n.
To see this, note that in the left-hand side of the above inequality there are at least n/2 terms, and each one of them is at least log (n/2) - 1 = log n - 2. This implies that
log (n div 2) + log ((n div 2) + 1) + … + log n ≥ (n/2) * (log n - 2).
We conclude that
log (n div 2) + log ((n div 2) + 1) + … + log n ≥ (n/2) * log n - n.
Finally, we have that n ≤ (n/6) * log n; note that this holds for every n that satisfies log n ≥ 6, or equivalently, for every n ≥ 2⁶ = 64, which we have already assumed. Thus,
(n/2) * log n - n ≥ (n/2) * log n - (n/6) * log n = (n/3) * log n.
To summarize, we just proved the following fact.
For every n ≥ 2⁶, (n/3) * log n ≤ log n! ≤ n * log n.
The above fact implies that we need Θ(n * log n) bits to write down the number log n!. In particular, this means that any algorithm that computes the number log n!will necessarily have to take time Ω(n * log n), since this is the time required just to write down the output.
Analyzing the performance of different algorithms
The two equivalent definitions of factorials that we saw in the beginning already suggest two algorithms, one iterative and one recursive, which are essentially equivalent in terms of running time.
The original definition of factorials suggests the following algorithm.
1) If (n < 2)
return 1;2) Let t = 1;3) For i = 2, ..., n:
t = t * i;4) Return t;
The above algorithm does n - 1 iterations, and each iteration multiplies two numbers. Moreover, for every i ≥ n div 2, the value of t is already big enough so that the number of bits required to represent it is Θ(n log n). Thus, for at least n/2iterations, the algorithm (for each such iteration) multiplies a number with Θ(n log n) bits with a number with Θ(log n) bits. Clearly, such a multiplication will necessarily take time Ω(n log n), since the length of the output is at least that much. It also takes time at most O(n log² n), if we use the fastest known algorithms for multiplication of integers. We conclude that the above algorithm has running time at least Ω(n² log n).
The recursive definition of factorials also suggests a very simple recursive algorithm.
FACTORIAL(n): 1) If (n < 2)
return 1;2) Return n * FACTORIAL(n-1);
It is easy to see that the above algorithm will perform the same operations, and in the same order, as the previous, iterative, algorithm. Thus, its running time is again roughly Θ(n²), ignoring some logarithmic factors.
Divide-and-Conquer delivers again
We will now describe a simple idea that drastically improves the running time. The starting point is the recursive algorithm we discussed in the previous section. The main issue that slows done that recursive algorithm is the fact that it performs Ω(n) multiplications involving numbers of size Ω(n log n). In other words, the “splitting-into-subproblems” strategy that it applies leads to a recursion tree that is a long chain of costly operations. So, one can ask whether there is another way of splitting into subproblems, such as the recursion tree is more shallow. This leads to the following idea.
For i < j, let Π(i, j) denote the product of the consecutive numbers from i to j. Clearly, for any integer n > 1, we have n! = Π(1, n). Moreover, for any integer t that satisfies 1 ≤ t < n, we have
Π(1, n) = Π(1, t) * Π(t + 1, n).
The above expression implies that we have many choices for partitioning our original problem into subproblems, with the recursive definition of the previous section just using one of these choices, namely t = n - 1.
Our goal now is to focus on the more general task of coming up with a fast algorithm to compute Π(i, j), for any i < j. Again, for any integer t that satisfies i ≤ t < j, we have
Π(i, j) = Π(i, t) * Π(t + 1, j).
Thus, we can write down the following algorithm-scheme for computing the number Π(i, j).
CONSECUTIVE_PRODUCT(i,j):1) If (i == j)
return i;2) Select integer t from the set {i,i+1,...,j-1} using some rule;3) Return CONSECUTIVE_PRODUCT(i,t) * CONSECUTIVE_PRODUCT(t+1,j);
We will use a very simple rule in Step (2). We will always set
t = i + (j - i) div 2.
In words, we pick t to be roughly the midpoint between i and j.
Let’s now think about the encoding length of the number Π(i, j). We can write
Π(i, j) = i * (i + 1) * … * j ≤ j * j * … * j.
The above product has j - i + 1 terms. This means that the encoding length of Π(i, j) is at most
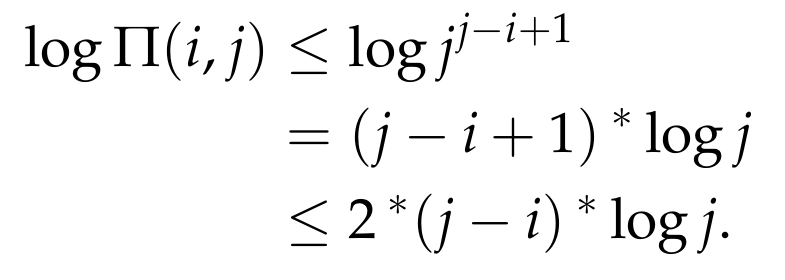
This implies that after the recursive calls of Step (3) have ended, the final multiplication performed at Step (3) takes time at most
O( (j - i) * log j * log (j - i) + (j - i) * log j * log log j ),
which is at most C * (j - i) * log² j, for some universal constant C > 0. Thus, if T(i, j)denotes the running time of the above algorithm with the rule we specified, we have
T(i, j) ≤ T(i, i + (j - i) div 2) + T(i + 1 + (j - i) div 2, j) + C * (j - i) * log² j.
For reasons that will become clear later, we call the term C * (j - i) * log² j the contribution of the 1st level of the recursion.
There is one last observation that we have to make. Let’s try to unravel the recursive steps. Since we split evenly into subproblems, after one level of “unraveling”, the problems Π(i, i + (j - i) div 2) and Π(i + 1 + (j - i) div 2, j) will have further been decomposed into the following problems, whose arguments roughly are
- (i, i + (j - i)/4),
- (i + (j - i)/4 + 1, i + (j - i)/2),
- (i + (j - i)/2 + 1, i + 3 * (j - i)/4),
- (i + 3 * (j - i)/4 + 1, j).
The contribution in the running time of the problems Π(i, i + (j - i) div 2) and Π(i + 1 + (j - i) div 2, j), can be split into the time needed to complete the aforementioned 4 recursive calls, plus the final additive term, which corresponds to the final multiplication, which, for each of the above 2 subproblems, is the equal to
C * (j - i)/2 * log² (i + (j - i)/4)) ≤ C * (j - i)/2 * log² j.
Thus, if we add them together, we get that the 2nd level of the recursion has total contribution of at most
C * (j - i) * log² j.
Continuing in a similar fashion, we can completely unravel the recursion and end up with a recursion tree. Moreover, since we are splitting evenly into subproblems, the depth of the recursion tree will be O(log (j - i)), and each level, for similar reasons as the ones explained above, will contribute at most C * (j - i) * log² j to the running time. Pictorially, the recursion tree looks as follows.
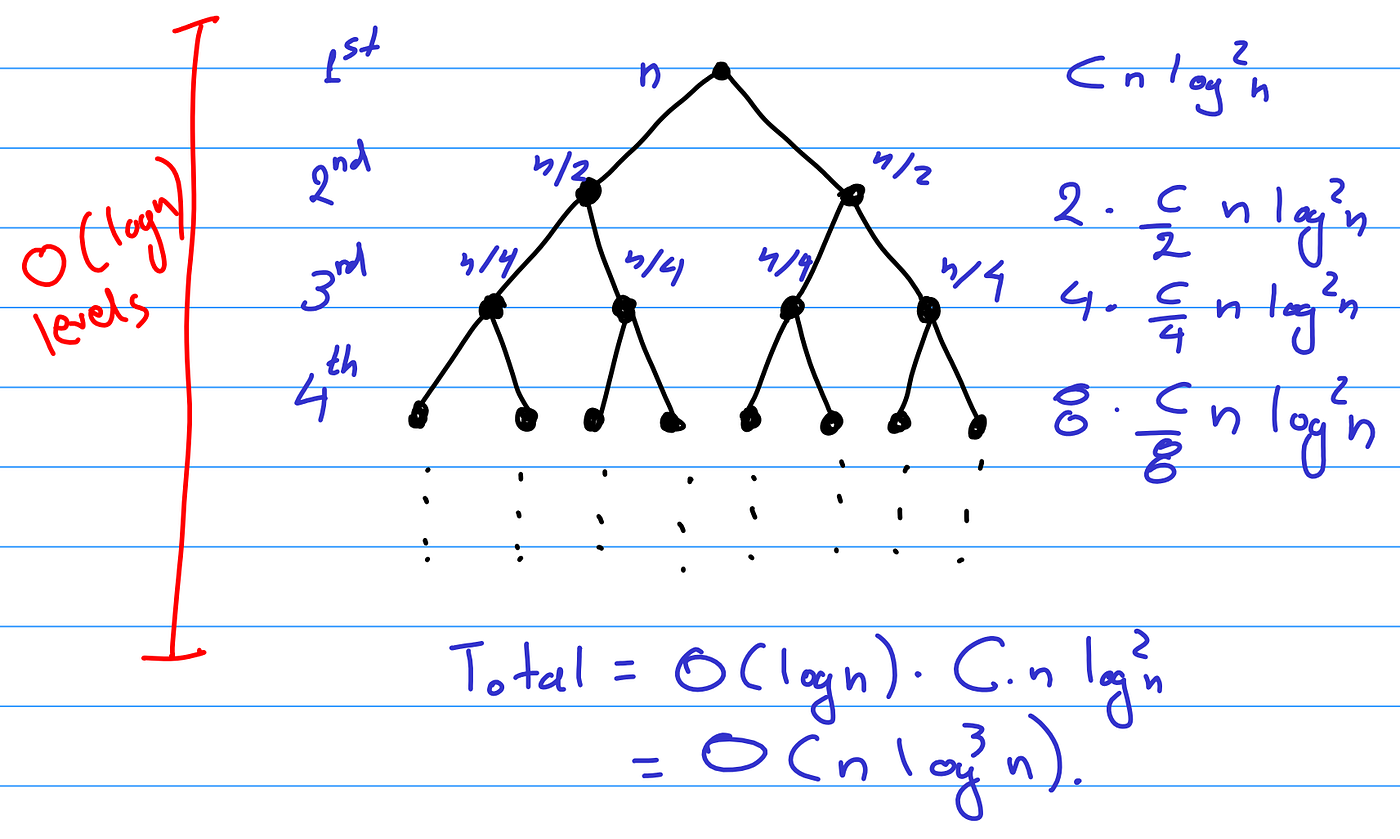
Thus, we end up with a total bound on the running time of
T(i, j) ≤ O( (j - i) * log (j - i) * log² j ).
Plugging in i = 1 and j = n, we conclude the following.
We can compute n! in time at most O(n * log³ n).
The above running time is a significant improvement compared to the quadratic (with respect to n) running times that we got when analyzing the two simple algorithms of the previous section. Up to logarithmic (in n) factors, this is an almost linear-time algorithm and is clearly almost optimal, as the time needed to just write the output is Θ(n log n).
Conclusion
In this article, we discussed a seemingly very simple question about how we can compute the factorial of a number. The Divide-and-Conquer approach discussed above is a significant improvement over the naive algorithms, but it is still not optimal. There is a slightly more involved algorithm that gives running time
O(n * log²n * log log² n),
by Peter B. Borwein and can be found here.
There is also a nice website maintained by Peter Luschny with implementations of several known algorithms, which can be found here.