Exploring Monotone Subsequences With Dynamic Programming in Python
When computer science and dynamic programming meets math

This is the code heavy addendum to the more mathsy article I wrote on the Erdos-Szekeres Theorem. However, this is also self-contained, and is focused on finding monotone sequences rather than proving things about their size.
Our task is to write a program to find the longest increasing subsequence in a sequence of numbers. And then to visualise the results!
For instance, the longest increasing subsequence in [1,2,3,0,4] is [1,2,3,4].
The mathsy result is quite astonishing. It says that for any sequence of n² different numbers, we can always find an increasing sequence of length n, or a decreasing sequence of length n.
Dynamic Programming Solution
In dynamic programming, we aim to memorise solutions to a smaller part of the problem to solve the larger problem. If the solution to the larger problem can be built from the smaller problems, then dynamic programming may be useful. The key insight here is that sometimes by removing the first element of a sequence, the longest increasing subsequence remains the same. A simple example of this is [100, 0, 1, 2, 3, 4, 5, -1], where the longest increasing subsequence is [0,1,2,3,4,5]. and when we remove the first element, the longest increasing subsequence of [0,1,2,3,4,5,-1] is still [0,1,2,3,4,5].
In this case, the longest increasing subsequence has to start somewhere. If it starts at the first element, then all we need to consider is the remaining elements which are larger. If it doesn’t then we just consider the smaller problem of all elements after the first.
Dynamic programming builds the larger solutions from the smaller solutions in this way, by working upwards.
What we will do is create a python dictionary. In the dictionary* we will map a number to the longest increasing subsequence starting at that points. (There are probably more memory efficient ways to encode the information). Then, we will use the information we have worked out for points later in the sequence to quickly solve for the longest.
*As each number will only appear once, this works fine. If the same number appeared multiple times we could use a tuple of number and position.
A Worked Example
Code will abstract this logic, and abstract logic is confusing, so let’s see it in action first.
Our sequence is [100,0,1,2,3,4,5,-1].
We first look at the last element of the sequence. The longest increasing subsequence starting at -1 is, unsurprisingly, of length 1, because this is the end element.
So, our dictionary currently has {“-1”: [-1]}.
Next, we look at an increasing subsequence beginning at 5. [5,-1] isn’t increasing, so once again the maximum length of increasing subsequence is 1.
Our dictionary now reads {“-1”: [-1]. “5”:[5]}
Next we get to 4. We want to solve this using our previous knowledge. So, we scan for elements which are larger than 4. 5>4. So the longest increasing subsequence beginning at 4 is [4] + [whatever the longest increasing subsequence starting at 5 is].
The use of the previous knowledge allows us to solve each step very simply. To work out the longest increasing subsequence starting at 0, we just find the numbers larger than 0 to the right hand side, and find the longest one, add 0 to the beginning, and add the new sequence to our dictionary.
Eventually, our dictionary will read:
{“-1”: [-1]. “5”:[5], “4”:[4,5], “3”:[3,4,5], “2”: [2,3,4,5], “1”:[1,2,3,4,5], “0”:[0,1,2,3,4,5], “100”:[100]}.
To find the longest subsequence, we just find the longest entry in our dictionary, or we update the largest element we have found as we create the dictionary. As both are O(n) time, it doesn’t make much difference which one we do.
Implementation
I would encourage you to try implementing this yourself! My code is nothing special — I’m not a coder by training (nor by experience), so what I present is fairly rough and ready.
First, we set up our function. It takes in an array (the sequence) as an input. Then we create a dictionary called scores_dict, and memorize the length of the sequence seq.
def longest_increasing_subsequence(seq):
scores_dict = dict()
length = len(seq)
Next, we loop over the sequence. Yes, I indexed from 1 to length+1, because I prefer it, even if it marks me out as a real amateur! If i==1, we are adding the last element of the sequence to our dictionary, which is just that element anyway.
Otherwise, we set up ‘current_best’ to keep track of our best option so far. Then, we loop over all elements later in the sequence. If they are larger than our current element, and they give a better score than our current longest increasing subsequence, then we update our longest subsequence accordingly. If an element is smaller than our current element, we ignore it.
This loop then completes the dictionary, working from the last element in the sequence backwards, until we have found out the longest increasing subsequence starting at every element. Then we return the dictionary, for the user to use as they wish! (they can extract the longest increasing subsequence in O(n) time, as previously discussed)
for i in range(1,length+1):
if i == 1:
scores_dict[seq[-i]] = [1, [seq[-i]]]
else:
current_best = [0, None]
for j in range(1,i):
if seq[-j] > seq[-i]:
if scores_dict[seq[-j]][0]+1>current_best[0]:
current_best[0] = scores_dict[seq[-j]][0] + 1
current_best[1] = [seq[-i]] + copy.deepcopy(scores_dict[seq[-j]][1])
else:
pass
else:
pass
if current_best[0] == 0:
current_best = [0, [seq[-i]]]
scores_dict[seq[-i]] = current_best
return scores_dict
Some elementary running time analysis
The overall solution has some easy upper bounds. The outer loop is length n, the inner loop performs less than O(n) operations, which gives a maximum running time of O(n²).
In contrast, the ‘naiive’ approach of searching through all the subsequences and identifying whether they are increasing and their lengths is exponential time. I first implemented this solution, which got slow at around n=7, and didn’t work on my computer (intel i5, two cores, 8gb ram) for n=10. In contrast, I could fairly comfortably run the dynamic programming solution when I tested it for n=100.
Some Visualisations
Graphs are pretty. So let’s see some ways to visualise this. First, let’s understand what the graphs below are representing.
Here we look at both longest increasing subsequence, and longest decreasing subsequence. I use Inc[x] to represent the length of the longest increasing subsequence starting at the number x in the sequence, and Dec[x] to represent the length of the longest decreasing subsequence in the sequence.
E.g., in our sequence [100,0,1,2,3,4,5,-1], Inc[0] = 5, as the longest increasing subsequence starting at 0 is [0,1,2,3,4,5], and Dec[0] = 2, as the longest decreasing subsequence starting at 0 is [0,-1].
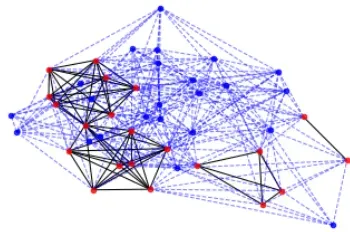
Each ‘dot’ (technically: node) of the graph represents one of the numbers in our sequence. I set n=49=7²
A connection is drawn between a node x and a node y if (Dec[x]==Dec[y] or Inc[x]==Inc[y]). E.g. in (4,5,6,1,2,3) we would connect node (6) with node (3), as the length of the longest increasing subsequence ending with (6) is length 3, and the length of the longest increasing subsequence ending with (3) is also length 3, so Inc(3)==Inc(6).
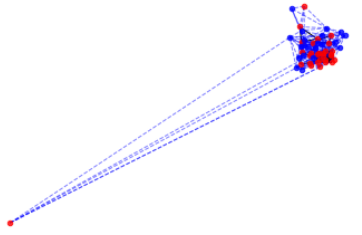
We colour a node red if the longest increasing subsequence, or the longest decreasing subsequence, ending at that point, is greater than root N. These red points therefore show us how often the condition of the theorem is met. I.e. a red point signifies the existence of an increasing or decreasing subsequence of length at least root N. Every diagram contains red points!

Next, we thicken some of the edges (‘connections’). We thicken the connections if they are a connection between red dots. This is to give some feel for the density of red dots.
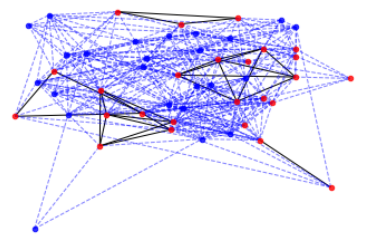
The code I used for this is below. It just adapts some of the documentation code I found on the networkx website. See here. It creates 10 graphs, by generating 10 random 49 digit sequences, finds the longest increasing and decreasing sequences for each digit, and adds the nodes as described using the dictionaries.
for i in range(10):
my_seq = [i for i in range(n)]
random.shuffle(my_seq)
G = nx.Graph()
for j in range(n):
G.add_node("a" + str(j)) #aj is the longest increasing subsequence starting at j
G.add_node("b" + str(j)) #bj is the longest decreasing subsequence starting at j
dict_a = longest_increasing_subsequence(seq=my_seq)
dict_b = longest_decreasing_subsequence(seq=my_seq)
for a_obj in dict_a.keys():
for b_obj in dict_b.keys():
if dict_a[a_obj][0] == dict_b[b_obj][0]:
G.add_edge("a"+str(a_obj), "b"+str(b_obj), weight=dict_a[a_obj][0])
else:
pass
pos = nx.spring_layout(G)
elarge = [(u, v) for (u, v, d) in G.edges(data=True) if d['weight'] > n/2]
esmall = [(u, v) for (u, v, d) in G.edges(data=True) if d['weight'] <= n/2]# nodes
nx.draw_networkx_nodes(G,pos,
nodelist=["a"+ str(i) for i in range(n)],
node_color='r',
node_size=20,
alpha=0.8)
nx.draw_networkx_nodes(G,pos,
nodelist=["b"+ str(i) for i in range(n)],
node_color='b',
node_size=20,
alpha=0.8)# edges
nx.draw_networkx_edges(G, pos, edgelist=elarge,
width=1)
nx.draw_networkx_edges(G, pos, edgelist=esmall,
width=1, alpha=0.5, edge_color='b', style='dashed')G.clear()
plt.show()
plt.clf()
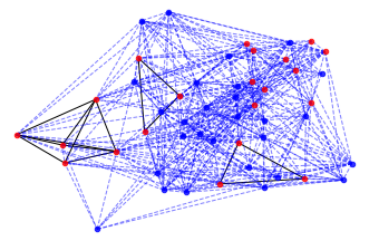
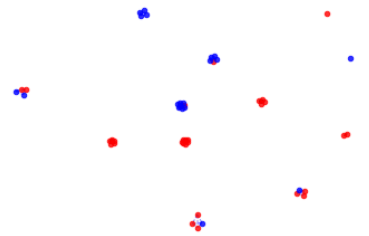
Now, let’s visualise in another way. Now, we only draw edges between two nodes if Dec[x] == Dec[y]. This visualises, for each point in the sequence, how many other points’ longest decreasing subsequence is the same length.

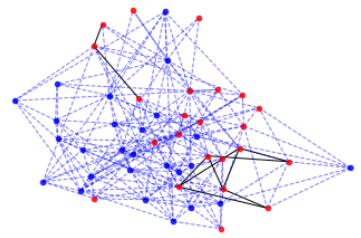
We can do the same for increasing subsequences. We now draw an edge between two nodes x and y if Inc[x]==Inc[y]. This visualises, for each point in the sequence, how many other points’ longest increasing subsequence is the same length.
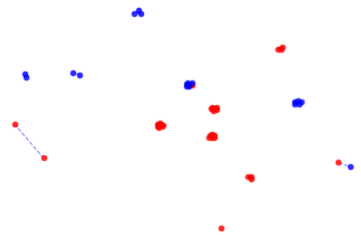
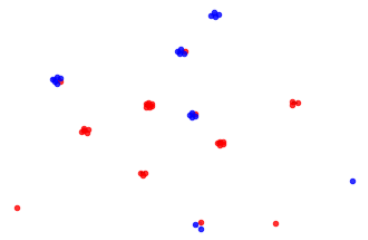
This visualisation is a neat way of illustrating the logic used in the Erdos-Szekeres Theorem I wrote about previously. You can check out what I wrote about that here!