A Guide to Inverting Matrices for Analysts

One of the oldest and most thoroughly studied problems in both linear algebra and numerical analysis is finding solutions for Ax = f. In a first linear algebra class, one might learn about how to identify what matrices are invertible, and calculate inverses by hand (very likely by means of Gaussian Elimination). Usually these calculations become unbearable if the dimension is larger than 3. On the other hand, a numerical analysis class will likely analyze how quickly these operations can be done, and maybe also discuss implementations of Gaussian Elimination, using a programming language such as Python or MATLAB.

While there is a lot of merit in knowing how to calculate inverses of matrices directly, I want to put a more theoretical spin on the concept of a matrix inverse. No, I’m not going to focus on what matrices truly represent in an abstract algebraic sense, but rather discuss some other criteria that indicate a matrix is (or is not) invertible. Obviously being able to find an explicit formula for the inverse is the best, but many tools exist for proving that a matrix is invertible, without actually identifying what that inverse matrix is. As we will see, invertibility is very closely related to the eigenvalues of a matrix, so as a “side effect” of our goal, we will also be exploring ways to calculate, or at least approximate, eigenvalues of a matrix.
Before diving into all of the other ways to show a matrix is invertible, let me make one other comment: there are often different versions of theorems and definitions of interest depending on whether the matrices we are working with have real entries, or complex entries. Usually the differences are pretty insignificant, though.
Determinants
Any matrix with a nonzero determinant is invertible (and vice-versa). This does not depend on the dimension of the matrix (of course, it needs to be square!). Thus if you can calculate the determinant of a matrix (which is doable in a finite amount of time if you know all the entries), you can figure out if the matrix is invertible.
This alone does not give the formula for the inverse of the matrix, if it exists. That being said, there is a connection between the value of the determinant and a formula for the inverse. The connection is most apparent for two-dimensional matrices, for which a formula is shown below:
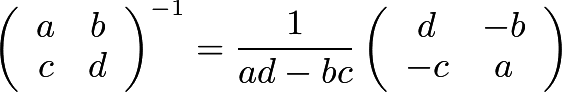
Of course, this formula only makes sense if the determinant of the matrix (precisely the denominator in the fraction above) is nonzero. If the determinant is zero, the formula above is algebraically undefined, just as we’d expect for a non-invertible (or singular) matrix.
Eigenvalue Criteria
The eigenvalues of a matrix are closely related to whether or not the matrix is invertible. Below are the associated definitions we need.
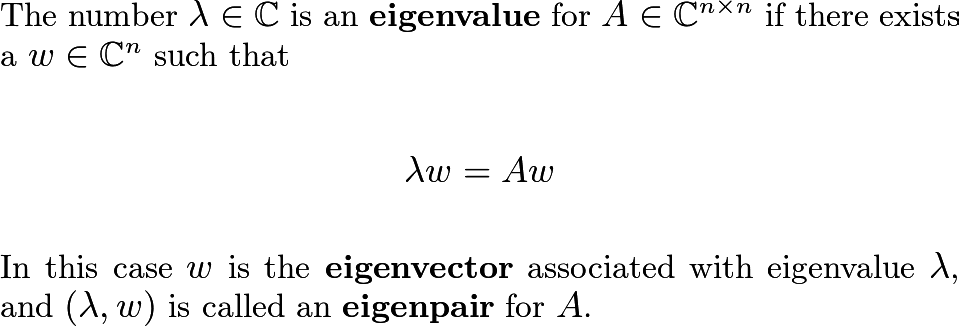
One well-known theorem in linear algebra is that a [square] matrix is invertible if and only if zero is not an eigenvalue. If you’ve taken a linear algebra class, you’ve probably seen or written out a proof of this result. Every matrix will have eigenvalues, and they can take any other value, besides zero. In some cases, one can prove that zero is not an eigenvalue by means of contradiction. That is, assume zero is an eigenvalue, and use that to reach some impossible conclusion. This is a method of proof used in many fields of mathematics.
The question that remains, which I will not fully answer here, is how to find the eigenvalues of a matrix. This in itself is a very broad problem, and there are many ways to approximate, if not outright calculate, the eigenvalues. However, it’s worth noting that it is easiest to find eigenvalues for diagonal matrices and upper/lower triangular matrices. For any of these matrices, simply read off the entries from the main diagonal.
Also, in some cases, the eigenvalues can be found via a similarity transformation: this means writing the matrix as a diagonal matrix, left and right-multiplied by a unitary matrix and its inverse, respectively. Then the diagonal matrix in the middle will have the same eigenvalues as the original matrix, when certain conditions are met. Numerical algorithms for finding these transformations have been studied for quite some time.
If you’re interested in learning more about eigenvalues, go to this Quora post.
Hermitian (Symmetric) Positive Definite Matrices
Let’s begin this subsection with two definitions that will be useful.
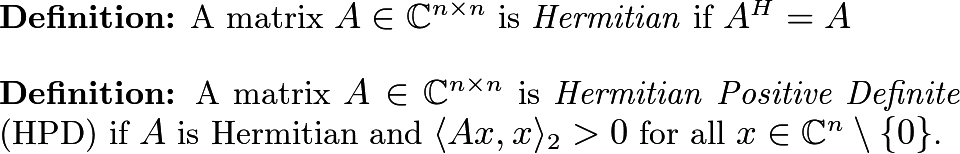
The inner product in the second definition is assumed to be the dot product. If these conditions can be checked directly, then the matrix is Hermitian Positive Definite. There are a number of properties of these matrices (abbreviated HPD matrices) that makes them very useful. In particular:
- The entries on the main diagonal are all positive real numbers
- The eigenvalues of the matrix are all real and positive.
The first condition actually gives a quick way to “filter out” matrices that may not be HPD. If the main diagonal has any entries that are either complex-valued, or real-valued but nonpositive, then the matrix cannot possibly be HPD. Along the same lines, a matrix that is not Hermitian cannot possibly be HPD.
Since an HPD matrix only has positive eigenvalues, zero cannot be one of the eigenvalues. That means any HPD matrix is automatically invertible.
Strict Diagonal Dominance
The notion of strict diagonal dominance also gives another criterion for invertibility, with a relatively straightforward definition to check.
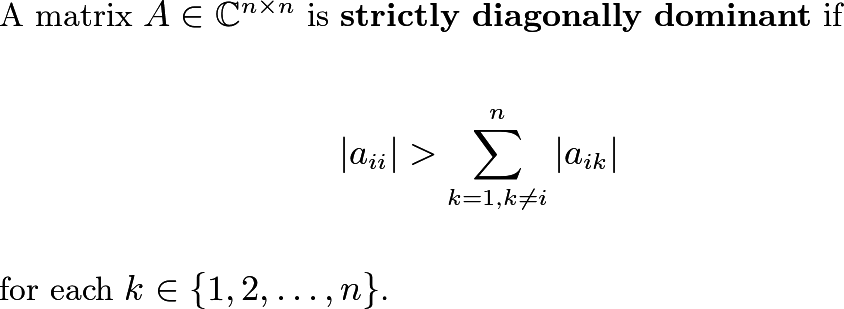
Among other things, it is known that a strictly diagonally dominant (SDD) matrix is invertible. It would be simple to write a script in a programming language of your choice to determine whether a given square matrix is SDD. For each row in the matrix, sum the moduli of all the entries in the row, except for the entry belonging to the main diagonal of the matrix. Then compare that to the modulus of the entry on the main diagonal, in the same row. So, for each row in the matrix, you are computing the modulus of n different complex numbers, summing n — 1 of them together, and then comparing the values of two real numbers (the two quantities on either side of the inequality in the above definition).
It is also worth noting that any diagonal matrix with no zeros on the main diagonal is SDD (and invertible, of course). Some upper or lower triangular matrices may be invertible while not being SDD. For instance, consider a lower triangular matrix with all 1s on the main diagonal and some really big number elsewhere in the lower triangular part of the matrix. For triangular matrices, the entries on the diagonal are the sole dictators of invertibility.
Gershgorin Discs
Gershgorin discs are circles in the complex plane that eigenvalues are guaranteed to be contained within. Each square matrix has a number of Gershgorin discs associated with it equal to the number of rows (or columns) in the matrix. Here’s a more formal definition.
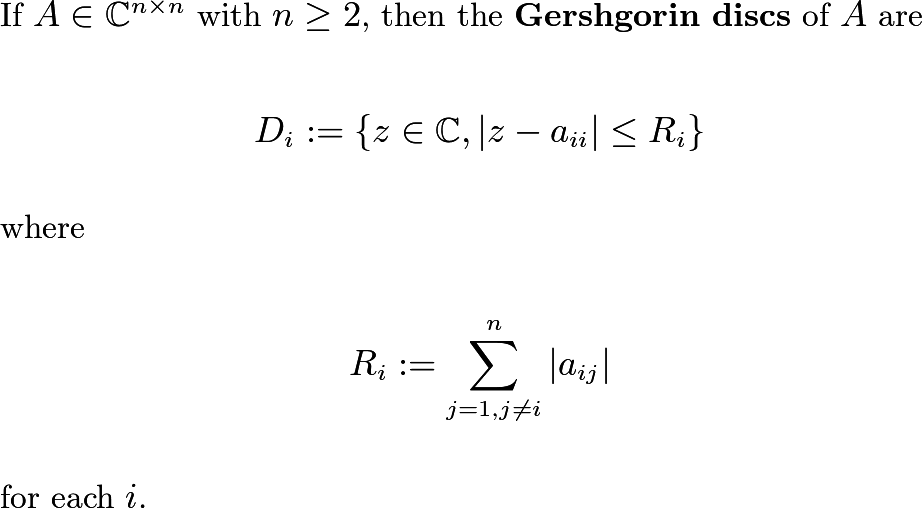
The entries of the matrix are all that are needed in order to compute all the Gershgorin discs associated with the matrix. But this has nothing to do with the eigenvalues of a matrix…yet. We need to introduce one other theorem about how these discs come into play. The First Gershgorin Circle Theorem states that all of the eigenvalues of a matrix are contained in the union of all the Gershgorin discs. Since each Gershgorin disc is a closed set, and the finite union of closed sets is itself closed, what we have is some larger, but still bounded, closed set within which all the eigenvalues of the matrix lie. If the origin is not in this larger closed set, zero cannot be an eigenvalue of the matrix. Then the matrix must be invertible.
There is a Second Gershgorin Circle Theorem, that gives information on how the eigenvalues of a matrix may be spread out across the different Gershgorin discs, but I won’t go into detail about that here. This theorem and a proof are contained in the freely available textbook I cite at the end of this article.
Neumann Series
The Neumann Series may look a bit odd at first, but really, it is based on a generalization of classical geometric series to matrices. The geometric series
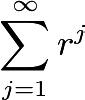
converges if and only if the modulus of r is less than 1 (r can be real or complex). In other words, it only takes a finite value in this particular case. You very well may have seen this in precalculus or calculus. That construction lends a touch of inspiration to the following theorem.
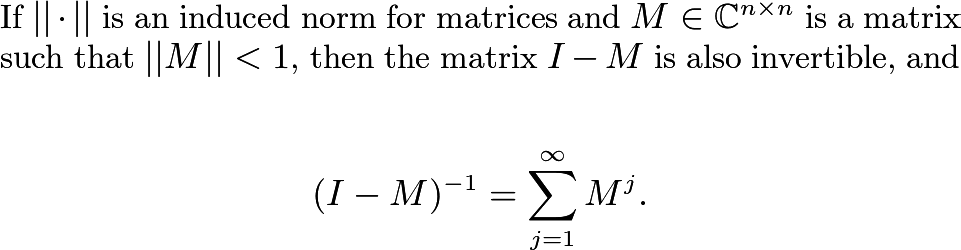
The formula for the inverse in this case looks just like a geometric series, but now the complex number r is replaced with a matrix M. Unlike many of the other theorems and definitions we discussed, this one does not pertain directly to eigenvalues, but it does give the advantage of an explicit formula for an inverse. Again, this is called a Neumann Series.
The matrix sum can be thought of as a matrix of infinite sums of complex numbers, and each of those sums must converge to some complex number. Otherwise, this inverse couldn’t have been well-defined to begin with!
Concluding Thoughts: Why Care About Invertibility?
As some concluding remarks, I want to briefly touch on some reasons why we might care to know that a matrix is invertible (and in some cases, what that matrix is). Many of the theorems I talked about in this article work two ways: they can assume some seemingly unrelated condition and “magically” conclude a matrix is invertible; the alternative is they assume a matrix is invertible, and we get to conclude some other property about the matrix. Here are some examples of what we may be able to find out about a matrix if we already know it is invertible.
- As I said before, the ability to solve [systems of] equations of the form Ax = f is a very powerful tool on its own.
- We may be able to learn more about the eigenvalues of a matrix. In particular, if a matrix is invertible, zero cannot be an eigenvalue. This often needs to be coupled with other information about the matrix, though. Remember, an n-by-n square matrix will always have n eigenvalues, including multiplicities. There are still many, many other values these eigenvalues can take.
- Some theorems, such as the Neumann Series representation, not only assure us that a certain matrix is invertible, but give formulas for computing the inverse.
- A strictly diagonally dominant matrix, as I said before, is an invertible matrix. That said, not all invertible matrices are strictly diagonally dominant (can you think of examples?) For such matrices, there exist estimates on the infinity induced norm of that inverse, in terms of the strict diagonal dominance of the matrix.
Acknowledgments: Many of the definitions and theorems I mentioned here are adapted from a draft of a numerical analysis textbook being worked on by Abner Salgado and Steven Wise. A link to this book can be found here (for free!).
I was lucky enough to take a course sequence with Salgado based largely on the contents of the book, though the commentary accompanying all the theorems and definitions is my own. It’s a way of expressing the intuition I developed for this content as I studied it